Polars moves fast. We typically release once a week. This process works well for us as we get features/improvements out
quickly and get user feedback, while we have that topic in cache. The downside of moving so fast, is that the typical
overhead of a release is brought to a minimum, we also want time to develop! What I mean by this “overhead” is taking
time to reflect and share all the improvements with our users by means of a blog. So this is an attempt to make good on
that neglect. The format of this and future blogs is to take an interval of releases (in this case 0.19.0 to
0.20.2), pick some highlights and explain a bit more about those.
Polars 0.19.0 was released on 30 August 2023. Since then up until Polars 0.20.2 we have made over 1000 contributions
to the project (1061 to be precise), ranging from minor tweaks to significant performance improvements. This can be a
minor doc improvement or a big feature we have been working on for weeks. In this blog you can find a selection of these
changes.
Note: Several benchmarks were executed to research the performance improvements. The benchmark ran on an m6i.4xlarge
(vCPU 16, RAM 64GB) instance type on AWS. The scripts are available as Github Gists. You can find the links to the Gists
at the end of this blog post, so that you can run it yourself as well.
1. Native parquet reader for AWS, GCP & Azure
Polars has mostly focussed on a local data. Since 0.19.4 we included an async runtime for reading from the cloud.
Initially this was pretty naive and we needed a few more iterations to make this performant. The challenge is finding
the proper concurrent downloading strategy while not downloading data you don’t need. We use this information from the
optimizer (projection and predicate pushdown), together with the metadata of the parquet files to determine which
files/row groups can be downloaded. In both the streaming and the default engine, we try to prefetch data whilst giving
highest downloading priority to the data we immediately need.
We benchmarked this against PyArrow’s parquet.read_pandas (which actually returns an Arrow table.) as baseline. We
also benchmarked this against other popular solutions and found Polars to be very competitive.
1.1 Dataset
The benchmark reads 24 parquet files of approximately 125 MB, with on average 21 row groups each.
1.2 Read all data
For this benchmark we read either all data:
Polars
(
pl.scan_parquet("s3://polars-inc-test/tpch/scale-10/lineitem/*.parquet", rechunk=False)
.collect(streaming=streaming) # streaming can True/False depending on benchmark run
)Pyarrow
pq.read_pandas("s3://polars-inc-test/tpch/scale-10/lineitem/")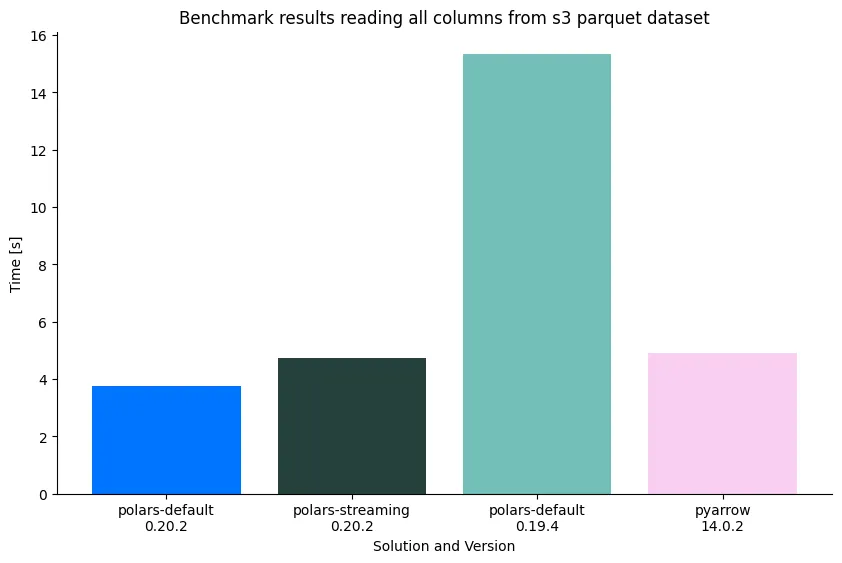
1.3 Read a single column
Or we select a single column. This allows the solution to only select the column data it needs.
Polars
(
pl.scan_parquet("s3://polars-inc-test/tpch/scale-10/lineitem/*.parquet", rechunk=False)
.select("l_orderkey")
.collect(streaming=streaming)
)Pyarrow
pq.read_pandas("s3://polars-inc-test/tpch/scale-10/lineitem/", columns=["l_orderkey"])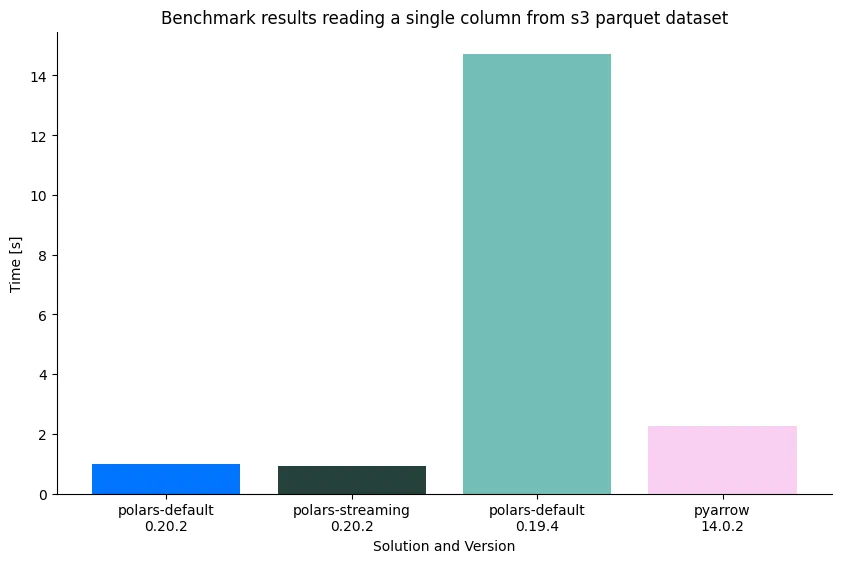
Note that we set rechunk=False because PyArrow doesn’t concatenate data by default, and we want both tools to do the
same amount of work. Polars parquet cloud reading can also make use of predicates (filters) in the query plan and based
on statistics in the parquet file (or hive partitions), choose to ignore a row group or a whole directory.
2. Enum data type (#11822)
Version 0.20.0 introduces the Enum data type, a new way of handling categorical data. It guarantees consistent
encoding across columns or datasets, making operations like appending or merging more efficient without requiring
re-encoding or additional cache lookups. This is different from the Categorical type, which can have performance costs
due to category inference. However, it is important to note that the Enum type only allows for the use of predefined
categories, and any non-specified values will result in errors. Enum is a reliable option for datasets with known
categorical values, enhancing performance in data manipulation. Read more about the Enum data type and the benefits in
the User guide
Example of the using the new Enum type:
# Example 1
>>> enum_dtype = pl.Enum(["Polar", "Brown", "Grizzly"])
>>> pl.Series(["Polar", "Grizzly", "Teddy"], dtype=enum_dtype)
ComputeError: value 'Teddy' is not present in Enum: LargeUtf8Array[Polar, Brown, Grizzly]
# Example 2
>>> enum_series = pl.Series(["Polar", "Grizzly", "Brown", "Brown", "Polar"], dtype=enum_dtype)
>>> cat_series = pl.Series(["Teddy", "Brown", "Brown", "Polar", "Polar"])
>>> enum_series.append(cat2_series)
SchemaError: cannot extend/append Categorical(Some(enum), Physical) with Utf83. Polar Plugins
Expression plugins have made their entrance. These allow you to compile a UDF (user defined function) in Rust and register that as an expression in the main python Polars binary. The main python Polars binary will the call the function via FFI. This means you will have Rust performance and all the parallelism of the Polars engine because there is no GIL locking.
Another benefit is that you have all utilize all crates available in the Rust landscape to speed up you business logic.
See more in the user guide.
4. Algorithmic speed-ups
Polars makes many performance related improvements. Here we highlight a few of them that made solid improvements. The script to run the benchmark yourself can be found in this Github Gist.
4.1 Scalable rolling quantiles
Performant rolling quantile functions are hard. If you naively implement them you will have worst case $O(n \cdot k)$
behavior. which is $O(n^2)$ if $k=n$. Here n is the dataset size and k is the window size.
After we realized our rolling_quantile functions had terrible scaling behavior, we went back to the drawing board. We
implemented an algorithm that is a combination of median-filtering and merge sort. The result is a time complexity of
$O(n \cdot log(k))$. Below we show the rolling median result of
- Polars
0.20.2 - Polars
0.19.0 - pandas
2.1.4
The benchmarks runs the rolling_median function and computes the rolling median of 100M rows.
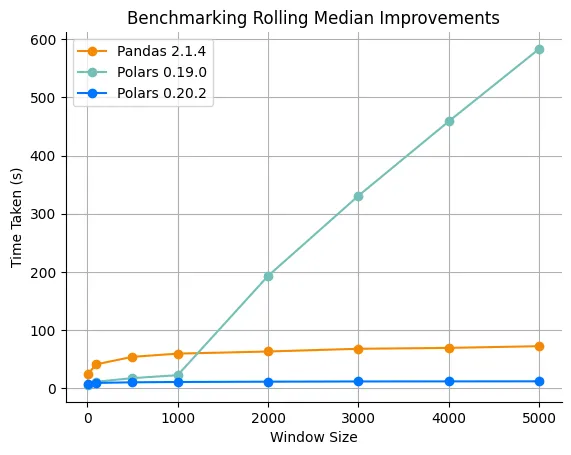
You can see that Polars 0.19.0 grows linearly with the window size and thus goes off the charts. No good.
4.1.1 Zooming in
If we look at only pandas and Polars 0.20.2, we clearly see the benefits of our new algorithm. Polars shows to scale
much better and has better performance across the board. Note that this is a single threaded benchmark. There may be
more improvements due to parallelism.
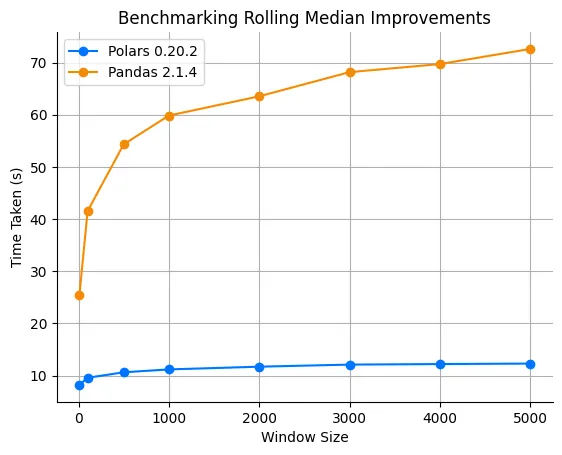
4.1.2 Scaling behavior
Increasing our window size really shows that we have $O(n \cdot log(k))$ complexity.
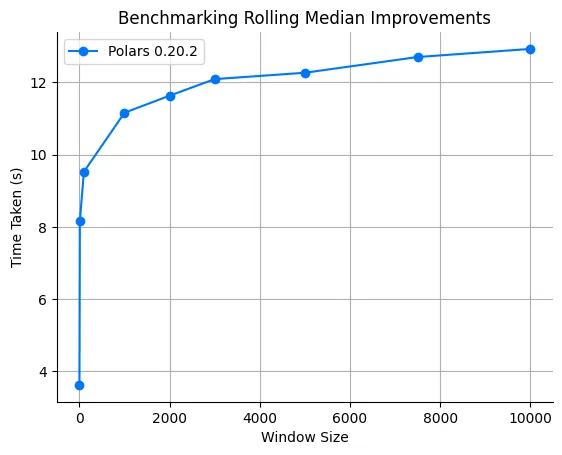
This initial rewrite of our rolling quantile functions, initiated more attention to our rolling kernels. At the moment we are rewriting them all and expect to be able to run our rolling functions fast, streaming and parallel (within the function).
4.2 Covariance and correlation
Covariance and correlation were still naively implemented in Polars. We now have given them proper attention and implemented a SIMD accelerated covariance and correlation. The snippets below show how to compute the covariance statistics in Polars.
4.2.1 Covariance in Polars
df.select(pl.cov("a", "b"))4.2.2 Correlation in Polars
df.select(pl.corr("a", "b"))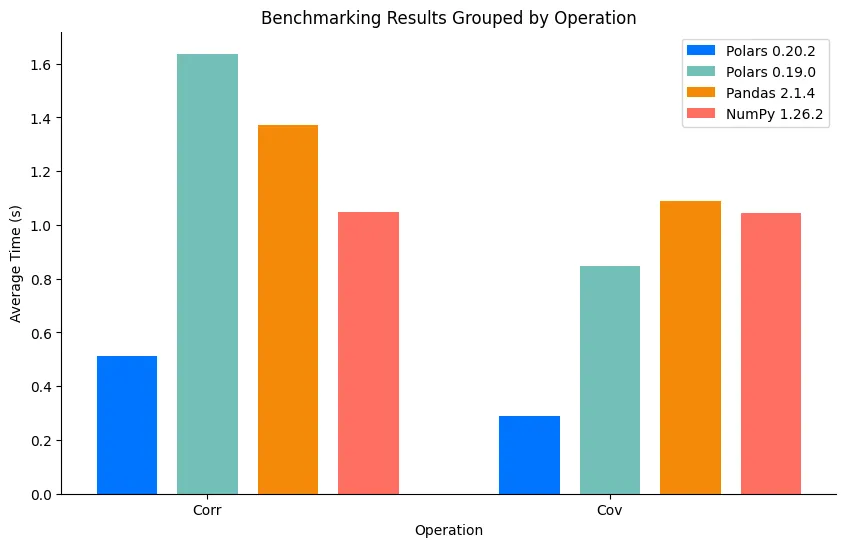
As can be seen in the image above, Polars has improved its performance more ~3x since 0.19.0 and is now almost at
least 2x faster than NumPy and pandas in this operation.
5. Syntax improvements
Polars aims to create a consistent, expressive, and readable API. However, this can be at odds with writing quick interactive code - for example, when doing some data exploration in a notebook. We can introduce shorter, alternative syntax, but we also want to avoid multiple ways to write the same thing.
With this delicate balance in mind, we have made a number of changes to facilitate fast prototyping.
5.1 Compact notation for creating column expressions (#10874)
The col function is probably the most used expression function in Polars. A shorter syntax is now available, taking
advantage of Python attribute syntax. Note that the ‘regular’ notation is still considered the idiomatic way to write
Polars code.
# Regular notation
pl.col("foo").sum()
# Short notation
pl.col.foo.sum()
# Shorter
from polars import col
col.foo.sum()
# Shortest
from polars import col as c
c.foo.sum()5.2 Compact notation for defining filter inputs (#11740)
It is now possible to provide multiple inputs to the filter function, which will evaluate to an and-reduction of all
inputs. Keyword argument syntax is also supported for simple equality expressions.
# Regular notation
df.filter((pl.col("a") == 2) & (pl.col("b") == "y"))
# Short notation
df.filter(a=2, b="y")
# Also works for when-then-otherwise expressions
df.select( pl.when(a=2, b="y").then(10))6. Support for Apache Iceberg (#10375)
By popular demand, the option to scan your Apache Iceberg files has been implemented with the help of our community. The implementation integrates with several catalogues and has field-id-based schema resolution. On top of that, you can also connect to your cloud environments (AWS, Azure or GCP).
Find more information to start using it today in the API reference documentation.
For more information about Apache Iceberg, you can visit https://iceberg.apache.org
7. Closing remark
On Github the Polars team has created a public backlog to show the issues that are accepted and what the team is currently working on. You can find the board on our Github page.
Are you working with Polars in your project(s)? Let us know! We are collecting interesting case studies and success stories to better understand how Polars is used by the community. You can share these with us at info@polars.tech or connect with us on the Polars Discord.
7.1 Benchmark scripts
Below the script that we used to run the benchmark scores in the blog post. Or you find them here as Github Gists: