Last couple of weeks I have been working on one, if not the, largest refactors of my life. We have completely rewritten the string/binary data structure we use in Polars. This was a refactor I wanted to do for a long time, but we couldn’t as several factors were not ready at the time.
Initially Polars was a consumer of the Arrow2 crate (native Rust implementation of the Arrow spec). This meant that we
couldn’t change the string type as the goal of the Arrow2 project was to follow the complete Arrow spec. End of last
year we forked parts of Arrow2 in the crate polars-arrow, which is a trimmed down implementation of the Arrow spec and
is tuned for Polars’ needs.
Now we have the code under our control the refactor was imminent. As luck would have it, the Arrow spec was also finally making progress with adding the long anticipated German Style string types to the specification. Which, spoiler alert, is the type we implemented. These changes are not user facing and the only thing that is required from a user perspective is upgrading to the latest Polars version.
If Arrow wouldn’t gone through with it, we would have. The goal of Polars is to have good interop with Arrow, but we might deviate from certain types if they better suite our needs.
1. Why the change?
Let’s take a step back. We haven’t touched on the reason for the change yet. The string type that was supported by the
Apache Arrow spec was defined by three buffers. If we ignore the validity buffer (that indicates if data is valid or
not), this is represented by Arrows’s default string type as follows. In the following example we hold a 3 rows
DataFrame with artist names:
shape: (3, 1)
┌────────────────────────┐
│ band │
│ --- │
│ str │
╞════════════════════════╡
│ ABBA │
│ The Velvet Underground │
│ Toots And The Maytals │
└────────────────────────┘All the string data would be stored contiguously in a single data buffer. And to keep track of the start and end of
the strings, an extra buffer was allocated containing the offsets (Yes signed integers, because Arrow needs to interact
with Java).

1.1 The good
The positive thing about encoding string data like this, is that it is rather compact. All string allocations are
amortized into a single buffer. This immediately has a downside as it is very hard to predict the size of your
allocation up front. Per string we only have a single 64bit integer overhead (ignoring the starting 0). Accessing the
string requires an extra indirection, but sequential traversal is all local, so this is definitely cache friendly.
1.2 The bad
As I mentioned above already pre-allocating the required size of data is hard. This leads to many reallocations and
memcopy’s during the building of this type. However, this downside is very relative. The huge (in my opinion
pathological) downside of the this data type is that the gather and filter operation on this type scale linear in
time complexity with the string sizes. So if you have $n$ rows and on average $k$ bytes in your strings, materializing
the output of a join operation would require $O(n \cdot k)$. This is ok if $k$ is small (which it often is), but when
there is large string (or binary) data stored, this gets very expensive.
Because a gather (taking rows by index) and filter (taking rows by boolean mask) are such core operations that are
used by a lot of other operations (group-by, join, window-functions etc.) having large string data could really
run a query to a halt.
2. Hyper/Umbra style string storage
The solution we (and the Arrow spec) adopted is designed by the
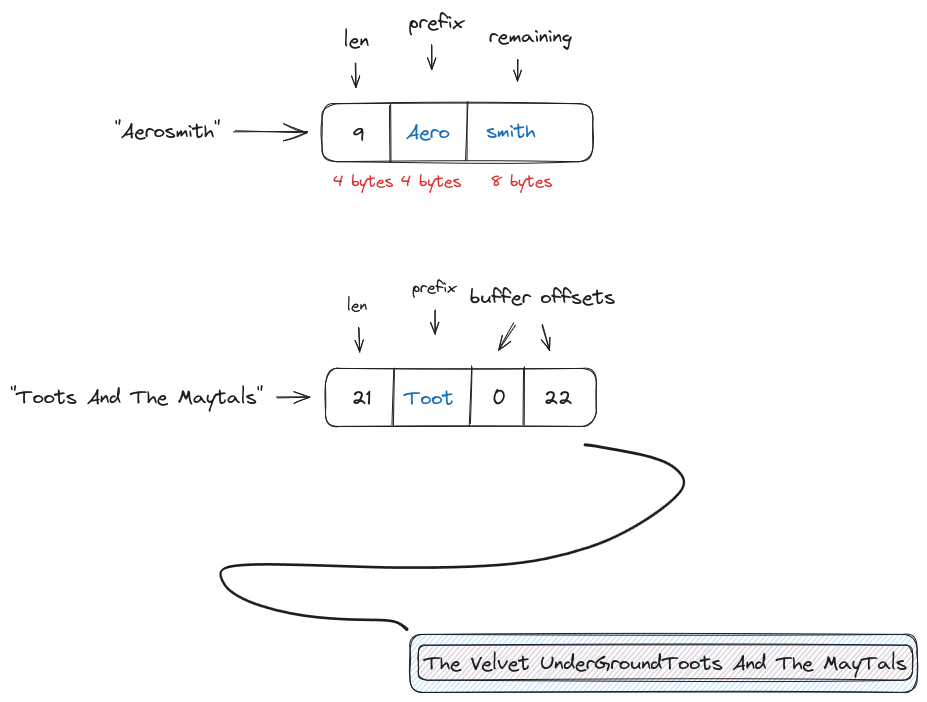
Hyper/Umbra database system. Here the strings are
stored as 16 bytes in a column (called a “view”). When the string has a length <= 12 bytes, the string data is inlined
and the view contains:
- 4 bytes for the length:
u32 - 4 bytes containing a prefix of the string data.
- 8 bytes stores the remainder of the string (zero-padded)
When the string is larger than 12 bytes, it is stored in a secondary buffer and the view contains:
- 4 bytes for the length:
u32 - 4 bytes containing a prefix of the string data.
- 4 bytes for the buffer index
- 4 bytes for the string offset (in the buffer)
2.1 The good
Storing string data like this has several benefits.
- For small strings, all string data can be inlined in the views, meaning we don’t incur an indirection on access.
- Because the views are fixed width and larger string buffers can be appended, we can also mutate existing columns.
- Large strings can be interned, which can save a lot of space and allows for dictionary encoding large string data in the default string data type. This is partially encoding, as we always need to allocate the views.
- Operations that produce new values from existing columns, e.g.
filter,gatherand all supersets of operations that use these, now can copy an element in constant time. Only the views are gathered (and sometimes updated) and the buffers can remain as is. - Many operations can be smart with this data structure and only work on (parts of the) views. We already optimized many of our string kernels with this, and more will follow.
2.2 The bad
As always, there are trade-offs. Every data structure also has some downsides, however for this one they are not pathological anymore. Downsides are:
- storing unique strings requires slightly more space. The default Arrow string has 8 bytes overhead per string element.
This binary view encoding has 16 bytes overhead per long string, or
4 bytes (length) + 12 - string lengthfor small strings. In my opinion, this is totally worth it considering we can elide an indirection and have fixed width random storage. - What I consider the biggest downside is that we have to do garbage collection. When we
gather/filterfrom an array with allocated long strings, we might keep strings alive that are not used anymore. This requires us to use some heuristics to determine when we will do a garbage collection pass on the string column. And because they are heuristics, sometimes they will be unneeded.
3. Benchmarks
This was a huge effort, and we are very glad this wasn’t in vain. Below we show the results various filter operations
with different selectivities (percentage of values that evaluate true). For each of this plot/benchmark we prepared a
DataFrame with 16 columns (equal to the number of cores) of string data. The string data was sampled with the
following patterns:
- small: sample strings between 1 - 12 bytes.
- medium: sample strings between 1 - 201 bytes, thereby mixing inlined and externally allocated strings.
- large: sample strings of ~500 bytes representing large JSON objects.
We use 16 columns because earlier Polars versions masked the pathological case by throwing more parallelism in the mix. By ensuring we use 16 columns, this extra parallelism will not help.
These benchmarks were run on a m6i.4xlarge AWS instance. The results
are huge improvement. Almost all cases outperform the old string type and the pathological cases are completely
resolved. As we go from $O(n \cdot k)$ to $O(n)$, the filter performance is completely independent from the string
length k.
4. More to come
Now Polars has its Arrow related code in its repository, we are able to tune our memory buffers more tightly for our use-case. We expect more performance increases to come from this, and are happy with the tight control we can now exercise over our full data-stack. Rewriting the string data-type was one such exercise. More to come!