Polars in Aggregate is a summary of what we have been working on in the past weeks. This can be seen as a cherry-picked changelog with a bit more context. This Polars in Aggregate is about the releases of Polars 0.20.17 to Polars 0.20.31.
CSV writer speed up (#15576)
Sometimes you get a great PR of someone who felt like spending their free Sunday on making something better. This is one of those. #15576 ensures we get dedicated serializer per datatype, minimizing function call overhead and type conversion.
This lead to a significant speedup in an already fast csv writer.
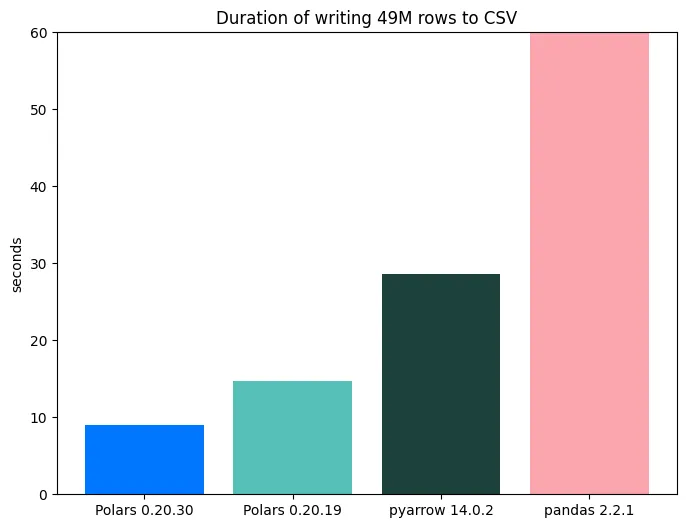
Benchmark
This benchmark was executed locally on a Macbook Pro M3 (2023) with 24GB of memory. 15 parquet files (~800MB) from the NYC Yellow Tripdata were read into memory and written to CSV. The results of Polars 0.20.30 are compared with those of version 0.20.19, which was released around the time of the previous Polars in Aggregate.
The benchmark shows a speedup of ~40%.
shape: (2, 2)
┌─────────┬─────────┐
│ version ┆ timing │
│ --- ┆ --- │
│ str ┆ str │
╞═════════╪═════════╡
│ 0.20.30 ┆ 8.975s │
│ 0.20.19 ┆ 14.684s │
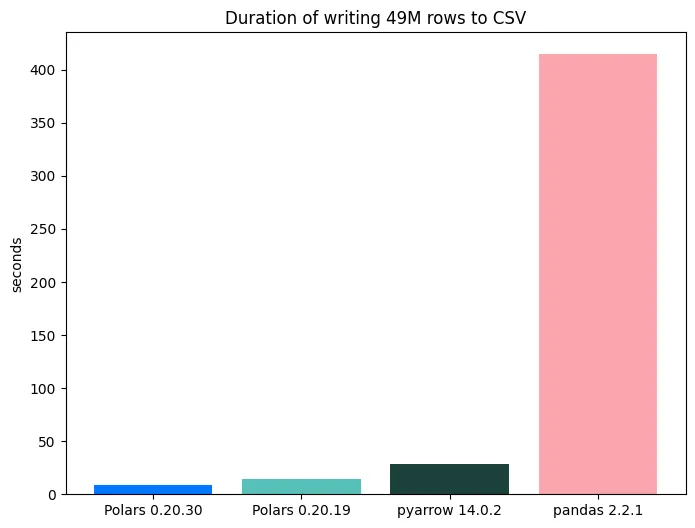
└─────────┴─────────┘In the plots below, we show the relative speedups, with PyArrow and pandas benchmarks as baseline. The latest Polars version is ~45x times faster than pandas and ~3.5x faster than pyarrow.
Cluster with columns & dead expression elimination (#16274)
In #16274 we have added a new optimization to the Polars optimizer. The
cluster with_columns optimization pass removes redundancies in several common usage patterns of the with_columns
function. The query optimizer now evaluates for sequential calls to with_columns:
- Can we reduce the amount of calls to
with_columns? - Are there column assignments that are never used and can be removed?
To illustrate, here is an example:
df = (
df.lazy()
.with_columns(height_per_year=pl.col("height") / pl.col("age"))
.with_columns(height_mean=pl.lit(0))
.with_columns(age=pl.col("age") - 18)
.with_columns(height_mean=pl.col("height").mean())
)Such queries were quite common, especially when trying to make code more maintainable or when making use of pipes.
Before this optimization, the engine just executed it with_columns by with_columns, which leads to redundant
evaluations and potential loss of parallelism.
The query optimizer now attempts to minimize the calls to with_columns and removes redundant expressions.
Consequently, the above query automatically gets reduced into the equivalent of the following.
df = df.lazy().with_columns(
height_per_year=pl.col("height") / pl.col("age"),
height_mean=pl.col("height").mean(),
age=pl.col("age") - 18,
)We went from four calls to with_columns to one call and removed the redundant assignment to height_mean.
Ad-hoc SQL on DataFrame and LazyFrame (#15783, #16528)
Besides the DataFrame API, Polars also allows querying LazyFrames and DataFrames with SQL. This SQL interface is
not new, but it was quite verbose to set up. This has now been made easier by providing a direct .sql method on
DataFrames.
Examples
df.sql()
from datetime import date
import polars as pl
df = pl.DataFrame(
{
"a": [1, 2, 3, 4, 5],
"b": ["zz", "yy", "xx", "ww", "vv"],
"c": [date(2024+i, 1, 1) for i in range(5)]
}
)
# You can mix and match the DataFrame API with SQL.
df.filter(pl.col("a") > 3, pl.col("c").dt.year() > 2025).sql("""
SELECT a, b, EXTRACT(year FROM c) AS c_year FROM self
""")shape: (2, 3)
┌─────┬─────┬────────┐
│ a ┆ b ┆ c_year │
│ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ i32 │
╞═════╪═════╪════════╡
│ 4 ┆ ww ┆ 2027 │
│ 5 ┆ vv ┆ 2028 │
└─────┴─────┴────────┘pl.sql()
Another addition is the pl.sql function under the polars namespace. This function will resolve the variables in the
global namespace and allows you to quickly run query on multiple sources.
from datetime import date
import polars as pl
df1 = pl.DataFrame({
"a": [1, 2, 3],
"b": ["zz", "yy", "xx"],
"c": [date(1999,12,31), date(2010,10,10), date(2077,8,8)],
})
df2 = pl.DataFrame({
"a": [3, 2, 1],
"d": [125, -654, 888],
})
pl.sql("""
SELECT df1.*, d
FROM df1
INNER JOIN df2 USING (a)
WHERE a > 1 AND EXTRACT(year FROM c) < 2050
""").collect()shape: (1, 4)
┌─────┬─────┬────────────┬──────┐
│ a ┆ b ┆ c ┆ d │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ date ┆ i64 │
╞═════╪═════╪════════════╪══════╡
│ 2 ┆ yy ┆ 2010-10-10 ┆ -654 │
└─────┴─────┴────────────┴──────┘Updated SQL documentation
Users have regularly asked which functions and operations are available in the SQL interface. With the release of Polars 0.20.31, this overview has been added to the Python API reference documentation (#16268). The growing list of functions and operations can be found here: Python API reference.
Seamless export to PyTorch and JAX (#15931, #16294)
DataFrames are often part of the pre-processing pipelines of ML models. Integration with PyTorch is therefore an often requested feature. Another machine learning library that has been gaining popularity recently is JAX.
Polars now exposes to_torch (#15931) and to_jax (#16294) methods to improve integration with these libraries. Here’s the to_torch functionality in action:
import polars as pl
df = pl.DataFrame(
data=[(0, 1, 1.5), (1, 0, -0.5), (2, 0, 0.0), (3, 1, -2.,25)],
schema=["lbl", "feat1","feat2"],
)
df.to_torch() # or df.to_torch("tensor")tensor([[0.0000, 1.0000, 1.5000],
[1.0000, 0.0000, -0.5000],
[2.0000, 0.0000, 0.0000],
[3.0000, 1.0000, -2.0000]], dtype=torch.float64)Under the hood, both to_torch and to_jax convert to NumPy first.
A lot of additional work has gone into improving this conversion step recently:
- Polars now natively supports converting all data types to NumPy
- Zero-copy support was added for
Datetime/Duration/Arraytypes - Performance on chunked data was improved in some cases
This means we no longer need PyArrow as a fallback.
The native conversion logic is now the default, and the use_pyarrow parameter has been deprecated.
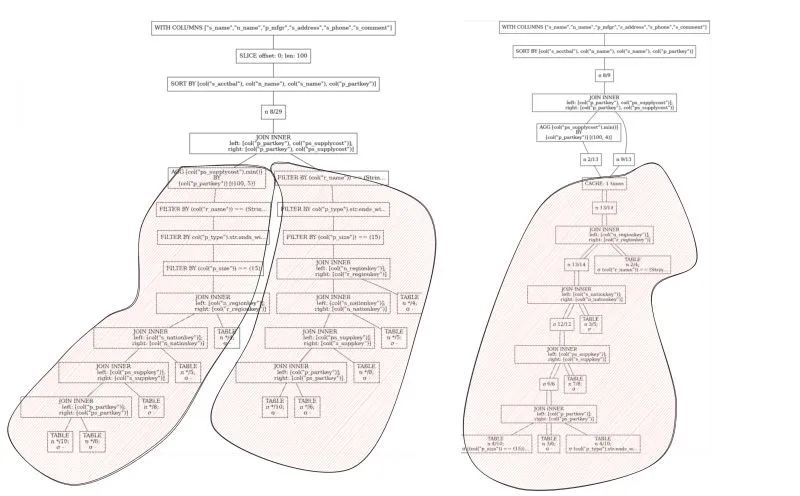
Full plan CSE (#15264)
Dataframe APIs are versatile. As a result of this, we often get query plans that are actually DAGs. This can happen, for
instance, when you concat or join parts of a query with a previous part (a self-join).
The image below shows the logical plan of query 2 of the TPCH benchmark. On the left we see a duplication of the query, and on the right we see how the optimizer now recognizes the duplication and ensures the engine only executes that part of the plan once.
Add field expression as selector with a struct scope (#16402)
Working with structs has gotten a lot more ergonomic with a dedicated with_field, pl.field and wildcard and regex
expansions in struct.field. Instead of manually deconstructing structs, single or multiple fields can now be updated
in a with_fields expression that behaves similarly to a with_columns context.
import polars as pl
from polars.testing import assert_frame_equal
df = pl.DataFrame({
"item": [{"name": "John", "age": 30, "car": None}, {"name": "Alice", "age": 65, "car": "Volvo"}]
})
# The full quantified syntax
verbose = df.select(
pl.col("item").struct.with_fields(
pl.col("item").struct.field("name").str.to_uppercase(),
pl.col("item").struct.field("car").fill_null("Mazda")
)
)
# Automatically expanded `pl.field` expression.
terse = df.select(
pl.col("item").struct.with_fields(
pl.field("name").str.to_uppercase(),
pl.field("car").fill_null("Mazda")
)
)
assert_frame_equal(terse, verbose)Unnesting structs can now also be inlined. Again, improving the ergonomics of working with nested data:
df.select(
pl.col("item").struct.field("^name|car$")
)outputs:
shape: (2, 2)
┌───────┬───────┐
│ name ┆ car │
│ --- ┆ --- │
│ str ┆ str │
╞═══════╪═══════╡
│ John ┆ null │
│ Alice ┆ Volvo │
└───────┴───────┘Redesigning streaming
We have started redesigning the streaming engine. This is far from finished, and we take it slowly as we want to make it right, but the initial plans look very promising. The current streaming engine will eventually be removed. At the moment we will fix bugs, but we will not add new operations to that engine as that effort would be in vain.
As preparation for this new engine, we are also improving our internal representation (IR). This is the data structure the Polars optimizer works on. Those changes are not user facing, but will result in better optimization opportunities. In a later post we will dive into the reasons for this redesign and our findings.
We are hiring new engineers
Rust backend engineer
As a founding Backend Engineer, you’ll shape the design of Polars Cloud in order to create a seamless experience for our users. Together with our product manager and full stack engineers, you transform requirements into technical design into implementation.
Database engineer
As a database engineer, you actively work on our DataFrame query engine. Together with the core team and a vibrant open source community, you shape the future of our API and its implementation. In your work, you’ll identify important areas with the highest community impact and start designing and implementing.
Full stack engineer
Together with our backend developers and product manager, you define our SaaS platform from the ground up. As a Full Stack engineer, you combine your frontend and backend skills to shape the design of Polars Cloud from conceptualization to deployment.