Polars now natively supports loading datasets directly from Hugging Face, applying query optimizations like predicate and projection pushdown to speed up downloads and data processing.
Hugging Face Hub
Hugging Face is a collaboration platform for the machine learning (ML) community. The Hugging Face Hub functions as a central place where users can share and experiment with open-source ML. One core element of this hub is datasets, which allows users to host their datasets in a structured and accessible manner. Polars now natively supports reading Hugging Face datasets. This allows you to easily manipulate and transform data for your ML model using Polars.
Reading
In order to read a dataset, we need to construct a Hugging Face URI. This describes the location at which Polars can fetch the data. A Hugging Face URI can be constructed as follows:
hf://datasets/repository/pathrepositoryis the location of the repository, this is usually in the format ofusername/repo_name. A branch can also be optionally specified by appending@branchpathis a file or directory path, or a glob pattern from the repository root.
import polars as pl
df = pl.read_csv(
"hf://datasets/commoncrawl/statistics/tlds.csv",
try_parse_dates=True,
)
df.head(3)┌────────┬─────────────────┬────────────┬─────┬───────┬─────────┬──────────────────┐
│ suffix ┆ crawl ┆ date ┆ tld ┆ pages ┆ domains ┆ pages_per_domain │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ date ┆ str ┆ i64 ┆ f64 ┆ f64 │
╞════════╪═════════════════╪════════════╪═════╪═══════╪═════════╪══════════════════╡
│ net.bt ┆ CC-MAIN-2014-41 ┆ 2014-10-06 ┆ bt ┆ 4 ┆ 1.0 ┆ 4.0 │
│ org.mk ┆ CC-MAIN-2016-44 ┆ 2016-10-31 ┆ mk ┆ 1445 ┆ 430.0 ┆ 3.360465 │
│ com.lc ┆ CC-MAIN-2016-44 ┆ 2016-10-31 ┆ lc ┆ 1 ┆ 1.0 ┆ 1.0 │
└────────┴─────────────────┴────────────┴─────┴───────┴─────────┴──────────────────┘The path may include globbing patterns such as **/*.parquet to query all the files matching the pattern. Additionally, for any non-supported file formats, you can use the auto-converted Parquet files that Hugging Face provides using the @~parquet branch:
hf://datasets/repository@~parquet/pathCode snippets
Hugging Face provides code snippets to make reading datasets in Polars even easier. Under “Use this dataset” you can find Polars:
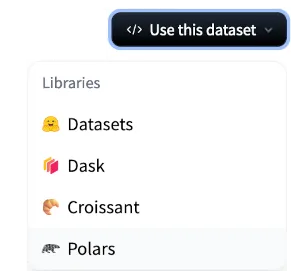
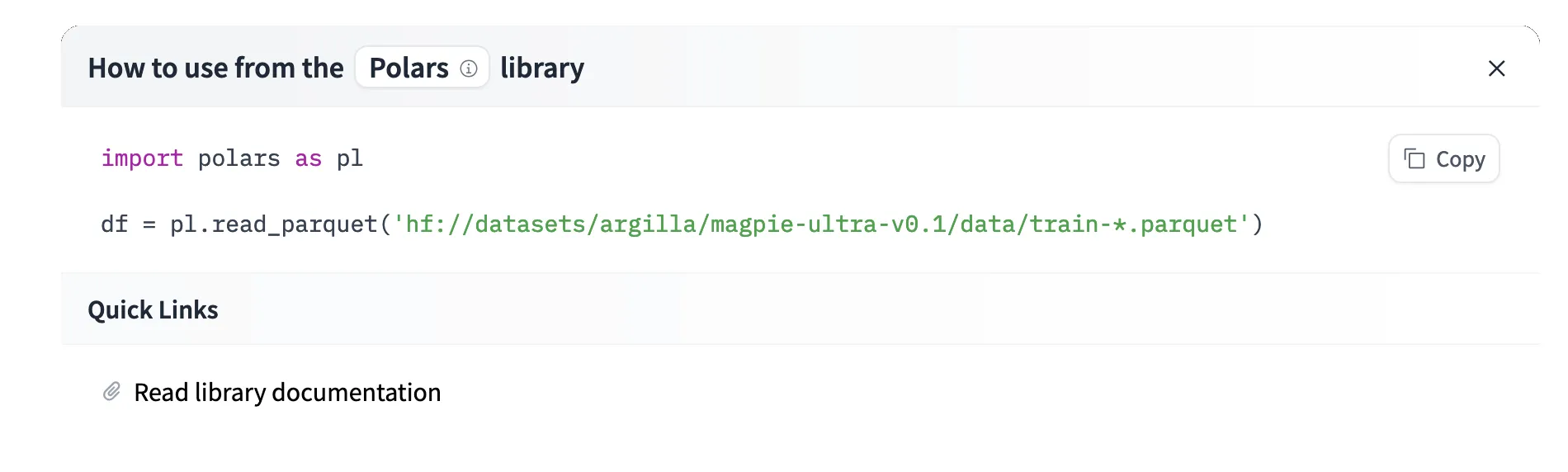
Clicking on Polars will show you the code snippet you can use to read the dataset including a link to the documentation.
Transforming
Once read, you can use the full Polars API to transform the machine learning dataset in any way you like. For example, we could calculate the total number of scraped pages per domain like this:
df.group_by("tld").agg(
pl.col("pages").sum()
).sort("pages", descending=True).head(5)Or we could use the lazy API to do it all at once. This has the added benefit that Polars will not read the entire dataset into memory, but only the columns and rows that are relevant to the query. This becomes even more beneficial for Parquet datasets where Polars can skip entire data regions from being transferred over the internet, potentially saving a lot of time.
pl.scan_csv(
"hf://datasets/commoncrawl/statistics/tlds.csv",
try_parse_dates=True,
).group_by("tld").agg(
pl.col("pages").sum()
).sort("pages", descending=True).head(5).collect()shape: (5, 2)
┌─────┬──────────────┐
│ tld ┆ pages │
│ --- ┆ --- │
│ str ┆ i64 │
╞═════╪══════════════╡
│ com ┆ 149959983274 │
│ org ┆ 18417978084 │
│ ru ┆ 11382068527 │
│ net ┆ 10774389510 │
│ de ┆ 8821759179 │
└─────┴──────────────┘Supported file formats
Polars supports the following file formats accessible under both the lazy variants scan_xxx and read_xxx.
- Parquet
- CSV
- JSON / New line JSON
Authentication
Hugging Face support private or gated datasets which are not publicly accessible. To access the dataset you need to provide the Hugging Face access token to Polars. You can create an access token at Settings -> Access Tokens or go to the following guide. Providing the access token to Polars can be done in three different ways:
By environment variable
HF_TOKEN=hf_xxxxxBy parameter
pl.read_parquet(
"hf://datasets/roneneldan/TinyStories/data/train-*.parquet",
storage_options={"token": ACCESS_TOKEN},
)By CLI
Alternatively, you can use the Hugging Face CLI to authenticate. After successfully logging in with huggingface-cli login, an access token will be stored in the HF_HOME directory which defaults to ~/.cache/huggingface. Polars will then use this token for authentication.
Conclusion
In short, integrating Polars with Hugging Face makes working with data and machine learning much smoother and faster. Polars handles big datasets efficiently, while Hugging Face provides a powerful machine learning platform. Together, they simplify the process from data preparation to model deployment.
For a more detailed explanation, check out the Hugging Face Polars documentation.