Polars 1.41 is out.
In this post we’ll go through three highlights: Parquet metadata decoding is significantly faster for wide tables, the query optimizer now eliminates redundant subplans at every nesting depth, and LazyFrame.gather is now available.
Faster Parquet Metadata Decoding
PR: #27427
Every scan_parquet call starts by reading and decoding the Parquet metadata stored in the footer.
The footer contains column statistics, row group metadata, and type information.
For wide tables with many columns or many row groups, decoding this footer was a measurable part of total scan time.
Thrift is the binary serialization format Parquet uses to describe its metadata structures. The previous decoder was auto-generated from the Thrift IDL definitions, which are general-purpose and built to describe arbitrary schemas. This auto-generated code had low performance and became a decoding bottleneck with with many small row groups or wide schemas. Since Parquet’s metadata schema is stable, 1.41 replaces that generic decoder with a hand-written one specialized for it, cutting unnecessary allocations and branches.
The metadata-decoding speedup scales with the number of columns:
| Columns | Before | After | Speedup |
|---|---|---|---|
| 100 | 2.12 ms | 1.32 ms | 1.61× |
| 1000 | 11.66 ms | 4.43 ms | 2.63× |
| 10000 | 117.4 ms | 35.74 ms | 3.29× |
Benchmarks measure footer decoding only (not full scan time) on Apple M4 Pro with uncompressed Parquet, 20 row groups, 1 row per group. Wider tables see larger gains because more column metadata means more Thrift to decode.
You don’t have to change anything in your code to get these benefits.
Existing scan_parquet calls get the speedup automatically.
Nested Common Subplan Elimination
PR: #27340
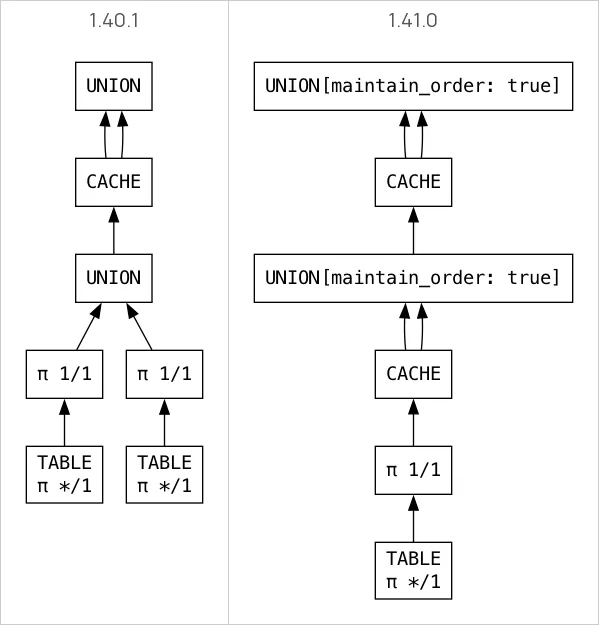
The Polars query optimizer detects when the same subplan appears in multiple branches of a query and replaces repeated evaluations with a single cached result. Before 1.41, this detection only worked at one level of nesting. A subplan shared across two branches would be deduplicated, but if the result was itself shared again higher up in the plan, the work was repeated.
1.41 fixes this by traversing into cache nodes during the elimination pass, so deduplication now applies at every nesting depth.
This example from the PR shows the pattern:
import polars as pl
lf = pl.LazyFrame({"a": [0, 1, 2]})
lf1 = lf.select(pl.col("a") + 1)
lf2 = pl.concat([lf1, lf1])
lf3 = pl.concat([lf2, lf2])
lf3.show_graph()lf1 appears twice in lf2, and lf2 appears twice in lf3.
Before 1.41, the outer concat is cached but the inner lf1 is still evaluated twice.
After 1.41, the optimizer traverses into cache nodes during the elimination pass, so both levels are deduplicated:
LazyFrame.gather
PR: #27501
DataFrame.gather() selects rows by integer index.
Until 1.41, this wasn’t available for a LazyFrame, which meant you had to materialize it first:
# Before 1.41
df = lf.collect()
result = df.gather([0, 2, 4])LazyFrame.gather() is now available, so row selection by index can stay in the lazy API:
import polars as pl
lf = pl.LazyFrame({
"product": ["A", "B", "C", "D", "E"],
"revenue": [100, 250, 80, 320, 150],
})
result = lf.gather([1, 3]).collect()
# Output
# shape: (2, 2)
# ┌─────────┬─────────┐
# │ product ┆ revenue │
# │ --- ┆ --- │
# │ str ┆ i64 │
# ╞═════════╪═════════╡
# │ B ┆ 250 │
# │ D ┆ 320 │
# └─────────┴─────────┘And More
The full list of changes is in the 1.41 release notes on GitHub.
Follow us for updates: