Since we announced the new accelerated GPU engine in April, both the NVIDIA and Polars teams have worked to provide a seamless experience and bring GPU acceleration to Polars. In this beta release, most common operations are covered and may benefit from GPU acceleration.
NVIDIA’s cuDF is part of the RAPIDS suite of CUDA-X libraries. It is a GPU-accelerated DataFrame library that leverages the parallel processing power of GPUs to significantly enhance performance in handling larger datasets.
With GPU-accelerated Polars, users can expect a performance boost up to 13x compared to Polars on CPU on compute-bound queries. This allows users to maintain the same interactive experience as their data processing workloads grow to hundreds of millions of rows.
In this release blog we will explain how to get started, what our design considerations are and what you can expect from GPU-accelerated Polars.
1. Python Polars
Let’s start with a slight disappointment. The new engine will only be available in Python Polars. At the time of writing, hooking into RAPIDS from Rust is far from trivial and would have been a much higher effort to pull off. The good thing about only supporting Python is that we could use cuDF directly and immediately support many operations while also having a clear installation story.
2. Getting started
If you want to dive right in, the new engine is available for Polars 1.6.0 and later on eligible machines. Start accelerating your queries in two simple steps.
To install GPU support, you must install polars[gpu] and add a --extra-index-url:
$ pip install polars[gpu] -U --extra-index-url=https://pypi.nvidia.comNext, you can collect your LazyFrames on the GPU by passing engine="gpu" to the collect method:
query = (
transaction.group_by("cust_id").agg(
pl.sum("amount")
).sort(by="amount", descending=True)
.head()
)
# Run on the CPU
result_cpu = query.collect()
# Run on the GPU
result_gpu = query.collect(engine="gpu")
# assert both result are equal
pl.testing.assert_frame_equal(result_gpu, result_cpu)2.1 Notebooks
You can try this out immediately in our interactive notebooks:
3. Design
3.1 Goals and constraints
Before we implemented the acceleration support, we set out a number of high-level goals in this work:
- we want to maintain the same semantics (obviously);
- we want to take advantage of the Polars query optimizer;
- queries that cannot be executed on the GPU should not fail and fallback transparently;
- using the GPU engine should not require that the end user has to import different packages;
- we want to support hybrid GPU/CPU query execution (not yet implemented);
For us, these constraints ruled out a “loosely-coupled” approach, where the GPU engine replicates the Polars Python API, and provides a second implementation. Instead, we have implemented a tightly-coupled approach where cuDF hooks in after the Polars IR (Intermediate Representation, explained below) is created from user input. Doing this means that all the semantics, Python type inference and optimizations are exactly the same and only the execution/acceleration differs.
3.2 Hooking in
3.2.1 Logical plan
As mentioned above, we have not created a cuDF API for Polars; instead cuDF is called by the Polars process during the execution of the physical query plan. Different from the streaming engine we are building (keep track as it will be something!), cuDF and the Polars in-memory engine work on whole data batches. This has the benefit that we can offload whole operations to cuDF very easily. Another benefit is that the optimizer has fed the IR with materialization hints. E.g. an operation knows how many rows it should produce and can therefore really save a lot of unneeded data materialization.
In the schema below we show the process of running a Polars query and at what point cuDF comes in. Let’s go through it.
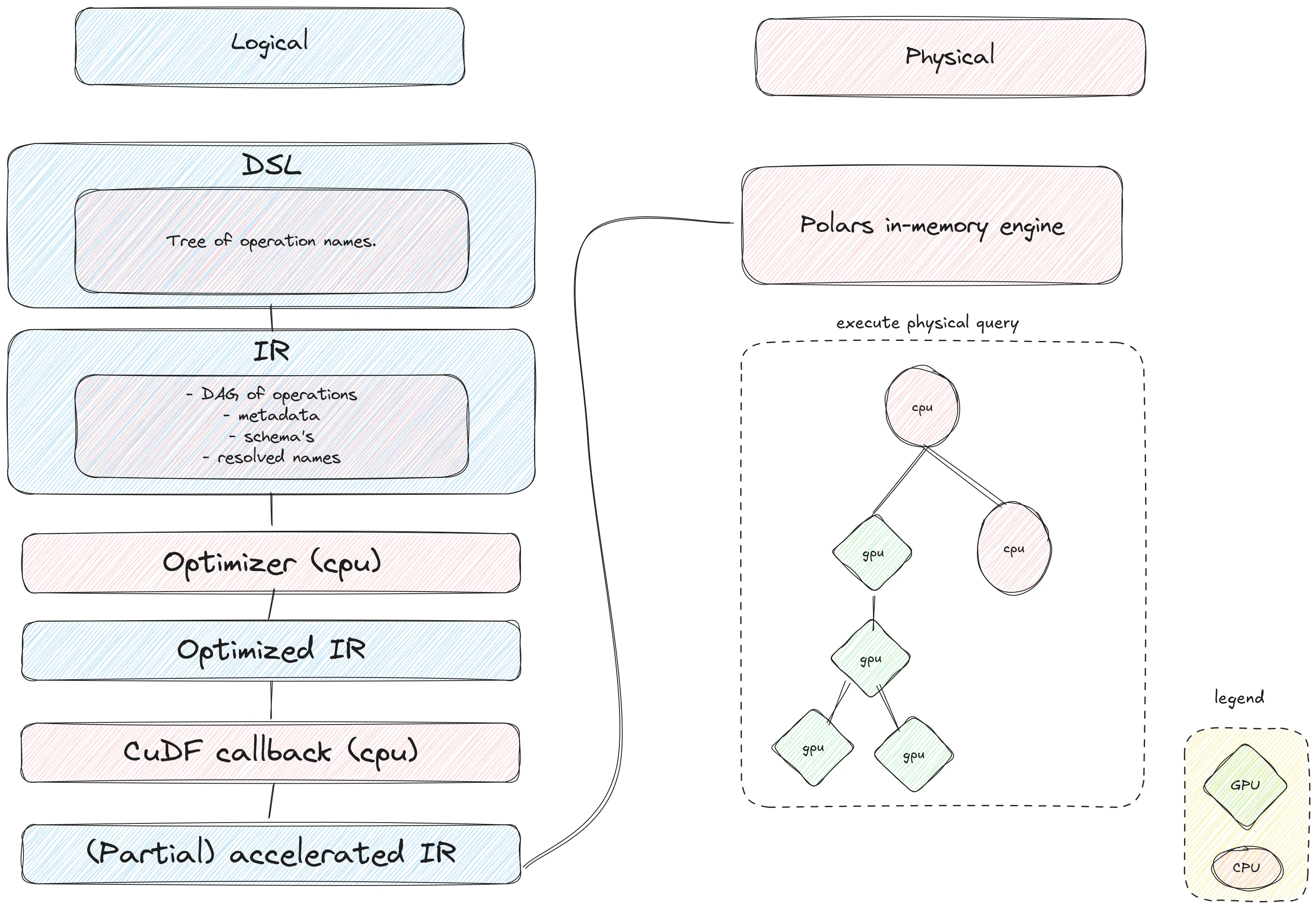
When you write a Polars query and run collect(engine="gpu"), the initial operations are the same as when you run on the CPU. We will build a DSL of the query. This is a tree structure containing all the operations of your query and is kind of similar to the AST of a programming language.
Next we convert the DSL to our IR. Here we validate the query for correctness, fetch and/or estimate metadata and determine the schemas of all operations. This is the base input for the Polars optimizer. The optimizer will try to re-order, simplify or simply remove operations. All with the goal of shorter query time and lower memory usage. What is left is an optimized IR. It is at this point that we call back into cuDF. Here cuDF will traverse the optimized IR and will try to replace entire subgraphs in the DAG with a Python callback that promises to return a DataFrame with the appropriate schema.
3.2.2 CuDF callback
Once Polars has built the optimized IR, we transition to the GPU engine. We use an inspector-executor design. In the first phase, we inspect the IR that Polars has built, building an execution plan (if possible), then we return that execution plan to Polars and actually execute it when the Polars physical engine runs. This allows us to provide transparent fallback at very low cost: we do not need to try and execute the plan on the GPU to determine that it will not be supported.
Suppose first, that all operations in the query are supported by the GPU engine. In this case, during traversal, cuDF builds its own representation of a physical plan that will execute on the GPU. Finally, at the end of traversal, we replace the top-most node in the IR with a new (opaque function) node that will execute the GPU physical plan. This new IR is then passed back to the Polars in-memory engine. The in-memory engine executes the plan as usual and when it reaches the new GPU-based node, the execution transitions to running on the GPU.
What about an unsupported query? Since the IR we are traversing contains full information about the query (for example, all datatypes, which operations are to be run, which options each operation uses), at this point we can decide statically (before execution) if an operation is supported by the GPU engine. The translation to cuDF encodes, for each operation, which set of datatypes and options it supports. When an unsupported operation is encountered, we stop the traversal and do not replace any nodes in the IR. At this point, we end up by returning an unmodified IR to the Polars in-memory engine, which executes the plan as usual as if no GPU had been involved. This typically adds a few milliseconds of overhead to unsupported queries.
Although not yet implemented, this approach can be extended to the case where the GPU engine only supports execution of a part of the whole query. For example, we might be able to run a grouped aggregation on the GPU, but a post-processing step might be unsupported. Right now, this would fall back to the CPU engine for the whole query. In the future, we will be able to execute the aggregation on the GPU and only fall back for the post-processing step.
4. Benchmarks
Users that are looking to speed up their queries can benefit from GPU hardware acceleration. Especially computational heavy queries, such as joins, group bys, string processing, etc. can see ~10x speeds from the GPU.
To validate this, we ran the GPU-accelerated beta on the PDS-H1 benchmark.
We compared an NVIDIA H100 PCIe with a Intel Xeon W9-3495X (Sapphire Rapids) CPU on local storage and 80GB of data. This shows that GPU acceleration can speedup your Polars queries up to 13x. For CPU-bound operations, GPU acceleration can make a lot of difference. The benchmark shows that not every query gets siginificantly faster, but it doesn’t cost you performance either. IO bound queries will not benefit from GPU acceleration, but we believe that here are many use cases that are CPU-bound by nature and will benefit from GPU acceleration.
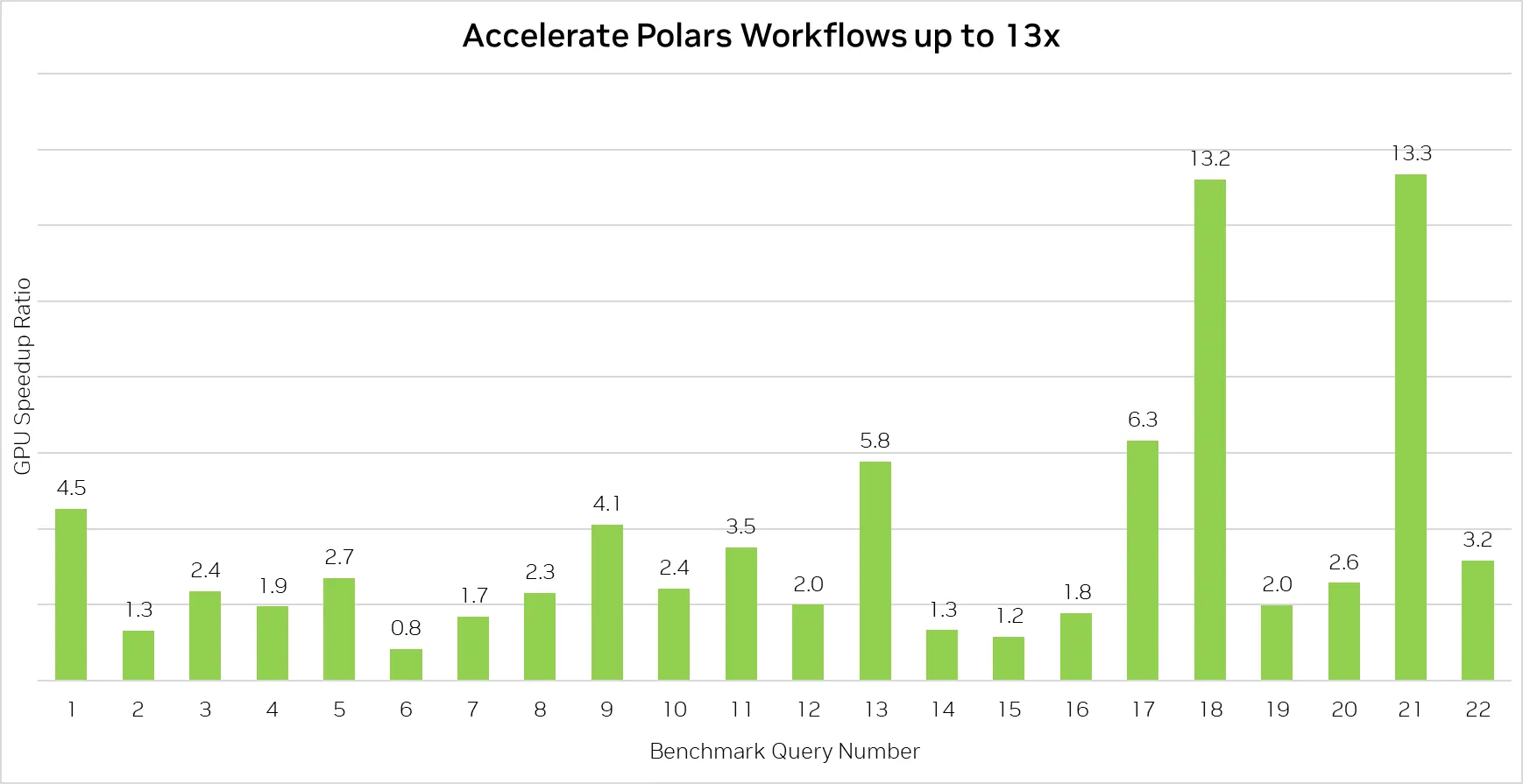 These are the speedups of the Polars GPU engine beta compared to the Polars default CPU engine across all 22 queries from the PDS-H1 benchmark at scale factor 80.
These are the speedups of the Polars GPU engine beta compared to the Polars default CPU engine across all 22 queries from the PDS-H1 benchmark at scale factor 80.
Aside from the speedups, we also noticed that the GPU acceleration scales better as the dataset size increases, showing that the CPU bottleneck increases on larger dataset sizes and the performance characeteristics of the GPU improves on increasing scale.
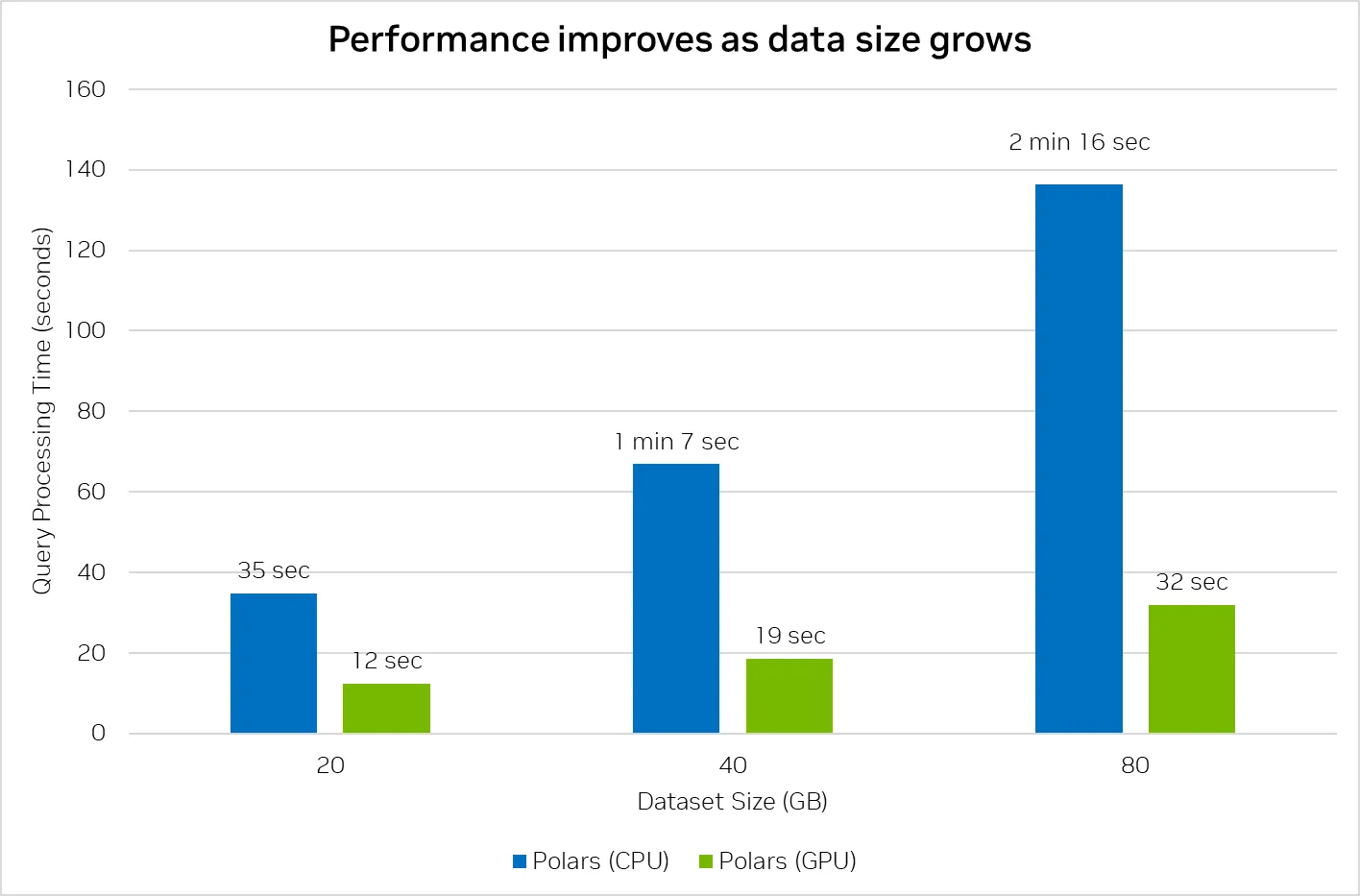 This chart totals the execution time of all 22 queries in the PDS-H1 benchmark across increasing scale factors.
This chart totals the execution time of all 22 queries in the PDS-H1 benchmark across increasing scale factors.
If we zoom in to the queries that have most performance increases, we see that those queries have a high number of group by and join operations, making those ideal for acceleration due to high amount of compute required.
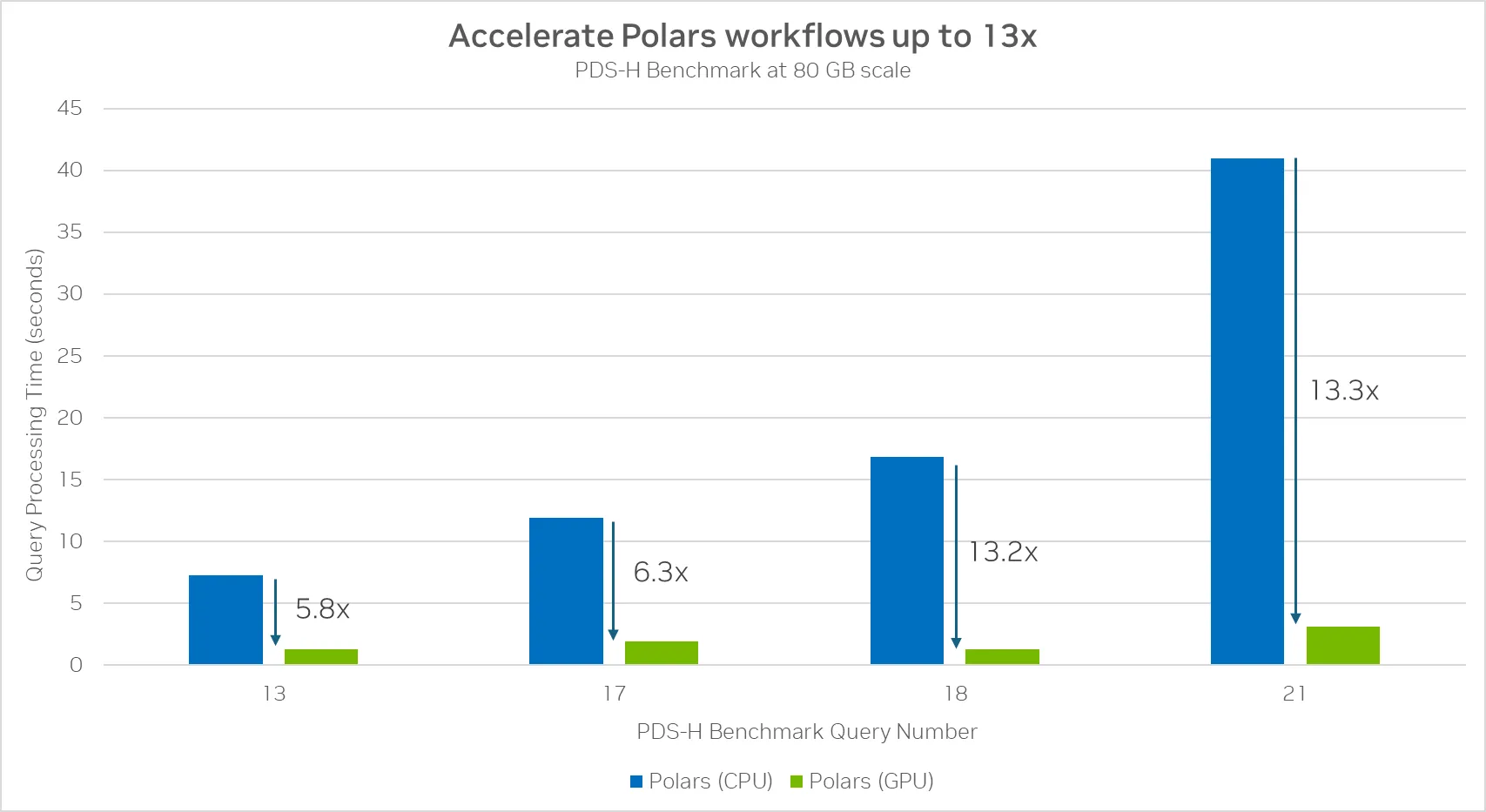 These are the four best speedups across a set of 22 queries from the PDS-H1 benchmark. The Polars GPU engine powered by RAPIDS cuDF offers up to 13x speedup compared to CPU on queries with many complex group by and join operations.
These are the four best speedups across a set of 22 queries from the PDS-H1 benchmark. The Polars GPU engine powered by RAPIDS cuDF offers up to 13x speedup compared to CPU on queries with many complex group by and join operations.
5. Addendum
Open beta considerations
This release is an open beta release, which means that you might experience some rough edges. We advise you to visit the Polars User Guide to understand potential limitations in this open beta. If you run into any issues or have any questions about the GPU engine, you can report them on the Polars issue tracker, where we’ll work together with NVIDIA to triage and respond to issues.
RAPIDS
NVIDIA RAPIDS is a suite of CUDA-X libraries for developers and data scientists to accelerate the most popular open-source data processing and machine learning solutions. Built on CUDA primitives for low-level compute optimization, RAPIDS exposes GPU parallelism and high memory bandwidth to deliver unparalleled speedups in analytics and machine learning tasks.
- Website: https://rapids.ai/
- GitHub: https://github.com/rapidsai/cudf
For further information and inquiries, you can reach us directly at info@polars.tech
Footnotes
-
This is a benchmark derived from TPC-H, but these results are not comparable to TPC-H results. See more details here. ↩ ↩2 ↩3 ↩4