
Preface
The Polars query engine, written in Rust, has interfaces for various languages, including Python, NodeJS, and R, with Python being the most widely used. However, there’s also a community-maintained Ruby interface that provides a wrapper to the Polars engine. In this case study, we explore the potential of using Polars for data processing and transformation in a Ruby project together with Vydia.
Vydia faced challenges as the number of uploaded CSV files and the data within them increased significantly. They have successfully switched from Ruby’s built-in classes to Polars to ingest and process these files. This reduced processing times from hours to minutes and led to a more manageable infrastructure.
About Vydia
Vydia is an end-to-end music technology platform and services company that provides labels with the infrastructure and tools to power their business. The company’s innovative solutions in rights management, automated royalty accounting, advanced payments, and daily performance analytics provide leaders in music and culture with the unfettered ability to publish, distribute and monetize their audio-visual content on a global scale. Vydia is a wholly-owned division of gamma., the artist-first multimedia platform providing creative and business services across all artistic and commercial formats founded by CEO Larry Jackson and President Ike Youssef.
Catching up with platform growth
Vydia’s royalty ingestion and transformation platform, built entirely in Ruby, faced growing challenges in handling the growth from tens to around a hundred uploaded CSV files. These CSV files average around 5 million rows (a 40% increase from the previous year), resulting in the need to process over half a billion rows a month. The inefficiencies inherent in Ruby led to the processing of these large CSV files taking several days, compounded by frequent runtime failures that necessitated manual intervention. This not only led to considerable computational and operational burdens but also resulted in significant overhead in developer and administrative resources for managing and cleaning up data.
To resolve these issues, Vydia is in the process of upgrading its database infrastructure, particularly focusing on optimizing analytics and earnings report generation for their users. The upgrade aims to substantially reduce processing times and enhance system reliability, directly benefiting finance and other dependent teams. A key technical improvement involved the ability to perform columnar operations and validations in bulk. In the original Ruby-based implementation, transformations and operations must be executed row by row, even when utilizing batch processing techniques. This row-wise approach is not only slow but also memory intensive.
In November of 2023, Vydia’s Software Engineering Manager, Danny Correia attended RubyConf where Paul Reece spoke about Polars. Shortly after the conference, seeing the potential of Polars, Vydia started several experiments using the Ruby interface of Polars. In the experiments, the engineering team built several proof of concepts using the default in memory API, lazy API, and batched CSV reader. Processing batches was the clear winner in terms of speed and memory efficiencies. It provided a much leaner approach and little overhead for implementation versus offloading the computing to an ETL pipeline. Refactoring and rewriting the current Ruby code only shaved off a few hours of processing time on 20+ hour running workers. This felt like a drop in a bucket compared to the speeds obtained in the PoCs with Polars.
Processing data in minutes instead of hours
The table below outlines the time required not only to process and transform the CSV files, but also to ingest the resulting data into a PostgreSQL database. While the benchmarks previously discussed focused solely on the CSV processing, which presented a significant bottleneck, this graph provides an overview of the overall time involved in the entire data handling workflow.
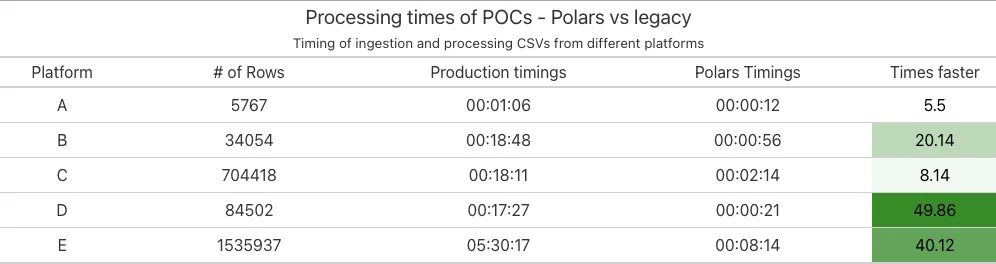
It’s important to highlight that the ability to stream data significantly mitigated the limitations imposed by Ruby’s garbage collection and memory allocation. By combining the Lazy API and batching features within Polars, Vydia successfully processed large CSV files in manageable chunks, avoiding the need to load excessive data into memory during runtime. Previously, their Kubernetes pods would frequently crash due to memory overload when using Ruby’s built-in classes for handling large CSVs. However, with Polars, Vydia maintained efficient memory usage, eliminating the need to increase the memory and computing power of their pods.

Polars adoption throughout the organization
The significantly reduced processing times have enabled the business to pay clients faster and more frequently. This creates opportunities for more complex and automated accounting processes, helping Vydia provide labels with even better infrastructure and tools to drive their business.
Internally, Polars has become the key tool for processing large datasets, whether originating from automated data pipelines, admin submissions, or user-generated reports. Based on the positive experiences and results seen by the Product Engineering teams, other teams are also exploring using Polars for their data processing use cases.
The implementation of Polars has not only enhanced the efficiency of data processing but also fostered a stronger collaborative environment between different data teams, creating a more unified approach to data processing and engineering practices across the company.
Polars is helping bridge the gap in technical discussions between product engineers and data engineers. We now have product engineers working on data transformation and consumption!
Danny Correia, Software Engineering Manager @ Vydia