Introduction
This case study is written by Isaac Robbins and Nelson Griffiths. Isaac is a data engineer at Double River Investments, where he oversees database management and data pipelines,
and develops tooling for interacting with data systems. Nelson is the Engineering and ML Lead at Double River and an active member of the Polars Discord.
Over the past months Nelson has inspired many users to explore Polars Plugins as he and his team have achieved incredible speed-ups and memory improvements.
With their successes with Polars plugins, they are excited to share their experiences here.
About Double River
Double River is a start-up hedge fund focused on doing quantitative analysis. We have a small team of 3 engineers and support a research
team with ~10 analysts. As part of the system’s team, we strive to provide robust and flexible infrastructure to handle daily pipelines that
process financial data and support the research team so they can focus on effective analysis that eventually feeds back into our daily
pipelines. Over the past 2 years, Polars has become core to achieving our goals at Double River by giving us increased performance, a
lower memory footprint, and a faster and more comprehensive development experience.
Learning to walk: Hello Polars
In the beginning, we had only heard whispers of the benefits of some mysterious, blazingly fast Python library that promised better
everything when it came to working with data. Our systems team had significant experience using pandas and NumPy and used them for
prototyping the first pieces of our data pipelines and trading strategy. Things were simpler back then. Simple calculations like calculating
returns from t-1 to t and missing value counts from different datasets. As we stumbled through the exploratory phase of building out our tech stack
and how to manage our pipelines, we began to explore Polars. Initially, we may have started testing it out because it written in Rust which
was good enough for us, but we soon started realizing that its claims were true, at least in our limited experience.
It started with one of our engineers.
Have you tried Polars yet?
It's only been a week and I think I'm better at Polars than I am at Pandas!
I filtered a DataFrame without suppressing warnings!
Then another. The same wonderful experience.
Within a month or so, it was clear that Polars was the way forward at Double River and that everyone, including our analysts, would need
to adopt it. No one wanted to be seen writing pandas in the office anymore.
But, while we were standing up the first pieces of our production pipelines and testing out Polars, our research team was busy working on
the more complicated and compute intensive stuff. They were implementing what we’ll call model A and model B, both involving significant
amounts of data (memory) and processing (compute). They were using pandas, NumPy, and statsmodels simply because that’s what they were
comfortable with. By the time we had everyone on board with Polars, most of these two pieces were too far developed to warrant an
immediate rewrite. As an organization, our focus was an MVP. Something in production was more important than something better not in
production. Over the next year, we released our MVP, started actually trading, and began iterating. We had transitioned most things to
Polars and everyone was now familiar with it. But, in terms of time to run and size of infrastructure needed, there were still two pieces of
our pipelines that stuck out like sore thumbs: model A and model B.
Once we were comfortable with Polars and our other workflows had steadied, it was time to face our demons.
Learning to run: Hello Polars plugins
Model A
Our first pass of our implementation of model A made use of pandas for data processing and statsmodels for regressions. By the time it
was ready for production we had replaced pandas with Polars for the data processing, which resulted in some noticeable improvements
but these were outweighed by some bigger issues. The nature of model A is complex but suffice it to say that the number of regressions
required is high. Like really high. These took up the vast majority of time to run the model.
Our model needed to be run each day, in entirety, from scratch. Unfortunately, we can’t simply store previous values and reuse them.
Furthermore, due to data availability, we have a relatively short window of time in which we needed to run our models so that all data gets
processed before the markets open. Using the statsmodels implementation of the regressions, our daily run would take around 120
minutes and use around 75GB of memory. Being fully on board with the benefits of Rust and its ability to be run as a Python package, we
wrote our own implementation for the regressions in Rust, imported it as a Python package, and swapped out the statsmodels
implementation. Running on the same machine, we saw immediate improvements resulting in each run taking around 80 minutes, again using
around 75GB of memory. We did nothing special with the implementation, rather, with the calculations in Rust, we were able to take
advantage of parallelization. While this was a huge win, there was still one remaining issue, the memory. In order to run the regressions we
had to transform all of the data from Polars to NumPy to Rust and then transform back from Rust to NumPy arrays and then back into Polars.
Just then, like an angel from the heavens, the Polars team announced plugins. With a little bit more Rust and a bit of help from the
Polars team, we were able to rewrite our regressions as a plugin. There are many benefits from using a plugin but two really stood out to
us:
- The data stays in
Polars, keeping memory down. - Get all the advantages of
Polarsparallelization for free.
With our new fancy
Polars expression for doing our regressions, we had slashed our memory down to 42GB and even saw the time drop down to 9 minutes. Yes,
you read that right. We went from nearly two hours to nine minutes. We were able to run our model in a fraction of the time and with a
a little over half the memory.
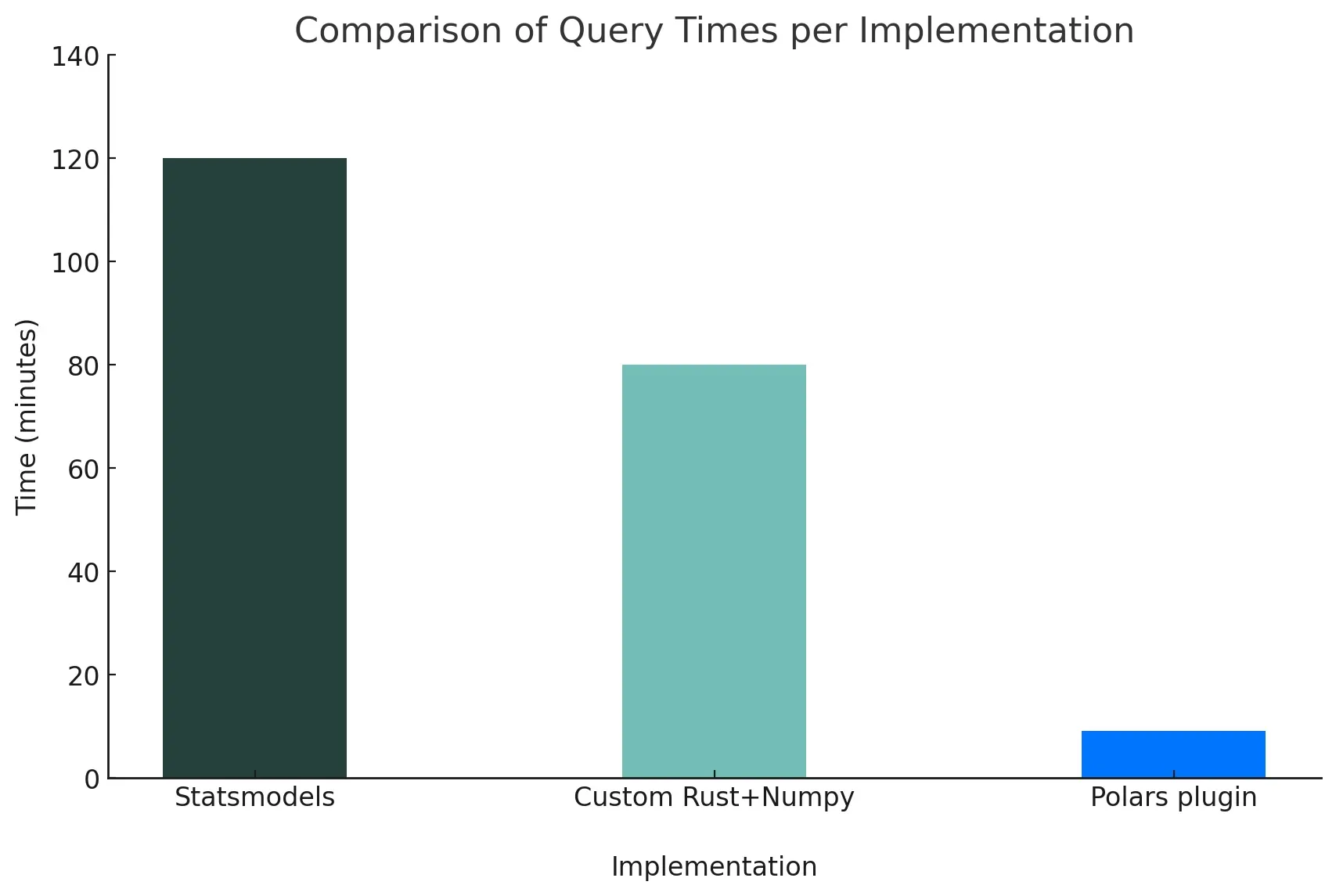
| Implementation | Time (minutes) | Memory (GB) | Relative Time | Relative Memory |
|---|---|---|---|---|
| Statsmodels | 120 | 75 | 1.0 | 1.0 |
| Custom Rust+Numpy | 80 | 75 | 0.67 | 1.0 |
| Polars plugin | 9 | 42 | 0.075 | 0.56 |
Lest anyone thinks our initial implementation of the regressions was optimized, we can assure you, it was not. We could have certainly done better with speed and memory.
But we are a startup sprinting towards a product and wrote a simple and straightforward implementation. What we found though, was that with
Polars plugins, we didn’t have to spend time in the weeds of optimization, we could do a mediocre job at rewriting it in Rust (which is quickly becoming a favorite pastime of ours).
Crisis averted, and it led to amazing results. We ended up with a mission critical pipeline that ran much faster and used far less memory on smaller,
cheaper machines. It was a win-win-win. And it was just the beginning of our journey with Polars plugins.
Learning to fly: Complex Polars plugins
Model B
Model B is yet another example of us choosing to implement amazing algorithms that will never win awards for computational efficiency. In
this case it required iteratively making and updating predictions for each step of a time series. Our initial implementation was written in NumPy
and was computationally efficient, but ran on a single group at a time. Instead of throwing more compute at the
problem and dealing with Python’s multiprocessing, we chose to harness Polars plugins. So, having successfully written our first plugin for the regressions in model A, all we wanted
to do was write more. Fortunately for us, model B just sat there every morning, running for 80 minutes, begging to be reimplemented as a
plugin. We soon obliged.
This implementation required quite a bit more care, as the number of steps and operations had grown significantly and there was a lot more to keep track of. But once we had figured it out it was glorious. The time it took to run model B went from 75 min to 6 min and the memory usage dropped from 41GB to 19GB.
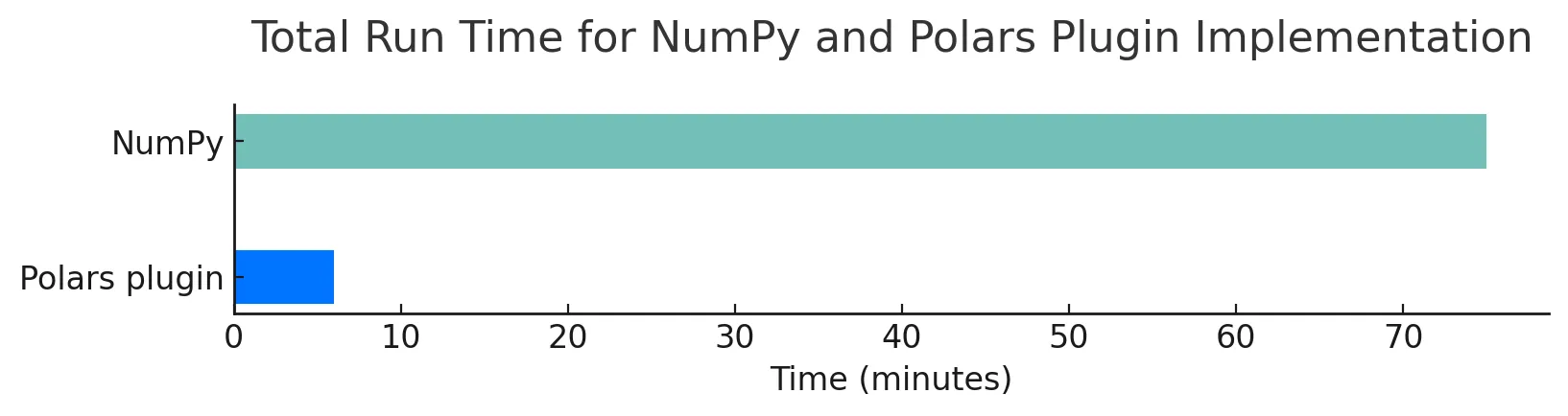
| Implementation | Time (minutes) | Memory (GB) | Relative Time | Relative Memory |
|---|---|---|---|---|
| NumPy | 75 | 41 | 1.0 | 1.0 |
| Polars plugin | 6 | 19 | 0.08 | 0.46 |
While we did have to rewrite our implementation of model B in Rust as a plugin for Polars , we did not change how it was implemented.
There were no algorithmic tricks or improvements to eek out some extra performance. Just the same set of linear algebra instructions in a
different language. We had gotten a 12x improvement in speed and a 50% improvement in memory by simply changing the context that
these calculations were being run in from Python and NumPy to Rust and Polars.
Conclusion
Polars is now one of the core beliefs at Double River. Whatever that means, we have fully embraced it. At first, it gave us some extra
speed and a bit more memory to play with. Soon, this translated into being able to run our data pipelines on significantly smaller
infrastructure. And if that wasn’t enough, our development times have gone down since Polars is simply easier to write. Eventually, the kind
people at Polars released plugins and that meant that we could take advantage of all of its amazing capabilities where it mattered most
by tailoring it to our very specific needs.
In doing so we saw a decrease in time to run our models which led to a 60% decrease in time to run our entire pipeline. We saw the memory usage of our most complex models drop by ~50%. All of these things combined have led to huge cloud savings and a much better product for our research team.
It’s now hard to imagine us without Polars. We are now able to and have done things that we previously didn’t even think possible. So
here’s to Polars and its team for their product and continued support!
Standardizing around Polars has been a huge win for us. The speed and memory benefits have been obvious.
The best part though is how easy it is to read and write. The collaboration between teams at Double River is
better than ever. We are all speaking the same language and it's Polars.
Nelson Griffiths
Engineering and ML Lead @ Double River
It's honestly insane how much of a difference using Polars can and does make. Developing with it is so intuitive. Speed and memory wise, it excels.
And with being able to extend it without limits through plugins, Polars is the definitive tool for working with data.
Isaac Robbins
Data Engineer @ Double River