Preface
This case study is written by Arnaud Vennin, Tech Lead Data Engineer at Decathlon. It offers insight into how more large organizations are discovering how Polars can make their data infrastructure more efficient, as Polars can handle significant data jobs on a single machine. This postpones the need to spin up compute clusters, greatly reducing complexity and overhead in their data infrastructures.
About Decathlon
Decathlon is one of the world’s leading sports brands, present in over 60 countries with more than 1,800 stores and a growing digital presence. Far beyond retail, Decathlon designs, develops, and distributes its own products and services through integrated research, innovation, and sustainable practices. This end-to-end approach reflects commitment to continuous progress, a comprehensive effort to push boundaries and envision a better future for sport globally.
The growing business generates a huge amount of data, which is handled by the data teams. For data engineers in the data department, the primary tool is Apache Spark, which excels at processing terabytes of data. However, it turns out that not every workflow has terabytes of data as input; some involve gigabytes or even megabytes.
Data Platform At Decathlon
The data platform architecture at Decathlon (figure 1) revolves around data workflows processed on cloud-hosted clusters where PySpark jobs are launched. A typical cluster consists of 180 GiB of RAM and 24 cores split across 6 workers. Data tables are stored on a data lake physically hosted on AWS S3 (in Delta table format) with a technical metastore managed by AWS Glue.
The data platform follows the multi-layered Medallion architecture, which organizes data into progressively refined zones (Bronze, Silver, Gold and Insight) to ensure data quality, governance, and accessibility. Pipelines are orchestrated using a managed version of Apache Airflow: MWAA. CI/CD is handled through GitHub Actions, which automates the testing and deployment of code packages. On the cluster, a package image is launched after being built in a container image to allow portability, isolation, and consistency across environments.
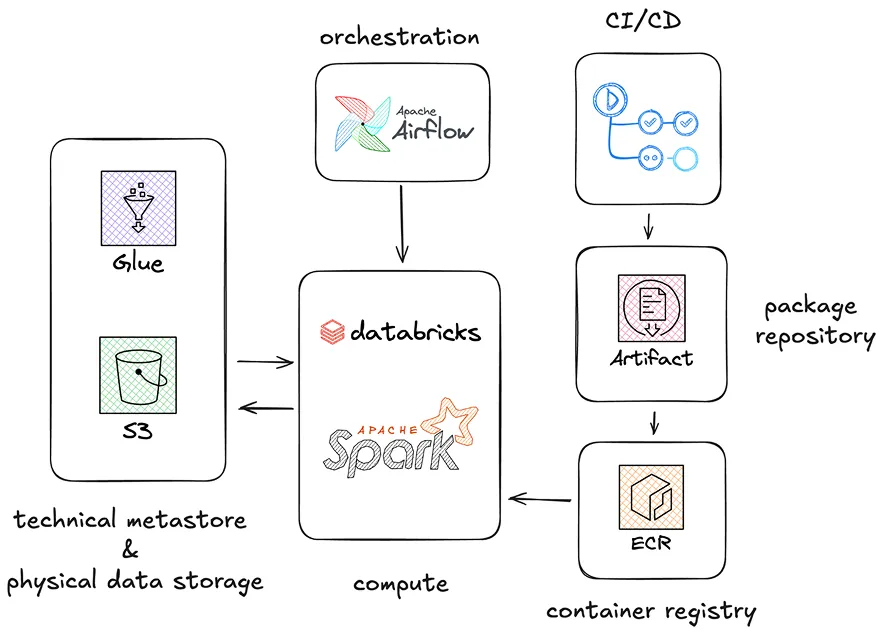
Figure 1 - Decathlon main data platform architecture
Here comes Polars
Alongside this main architecture, our platform team has made a solution available primarily for smaller input datasets (figure 2), originally intended to be used with pandas running on a managed version of Kubernetes.
As a team we had a couple of workflows running on it, but we soon ran into problems typical of the library: out-of-memory (OOM) errors when rather large datasets are loaded, and it did not handle Delta format easily (at least at the time when we started using Polars). We also considered using AWS Lambdas to launch Polars pipelines but our experience with the tool was lower than with Kubernetes.
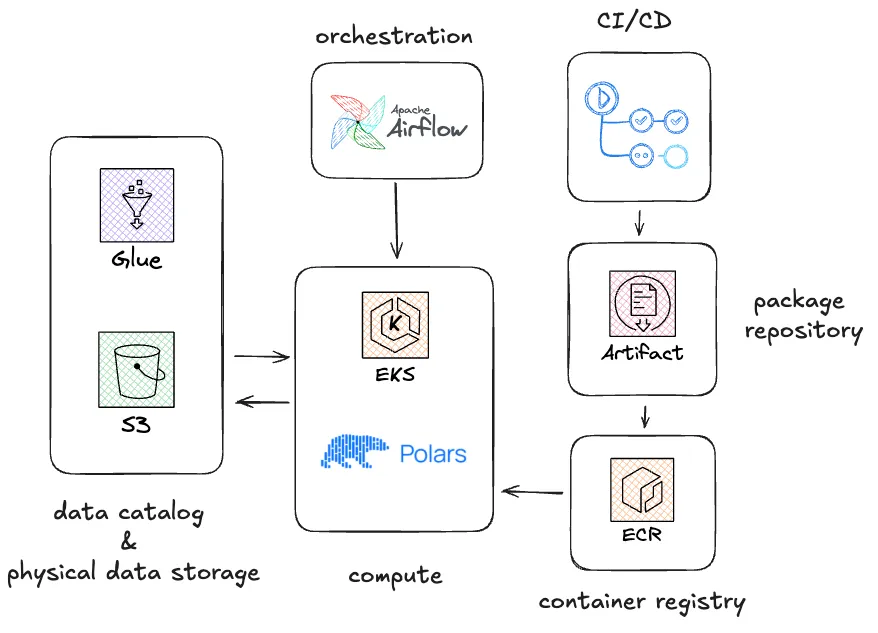
Figure 2 - Decathlon data platform architecture running Polars
We first heard about Polars after reading an internal documentation from our Principal Engineer suggesting to replace pandas with Polars. The first attempt and experience was promising. We were able to write a Delta table for small input datasets. The Polars syntax is similar in spirit to Spark’s, so we felt at ease using it.
Rapidly, we got the intuition that Polars could be suitable for more than just replacement of Pandas. So, we decided to migrate a Spark job to Polars. The biggest table of the job was 50 GiB in Parquet (equivalent to a 100 GiB CSV table or more). The table size was bigger than the Kubernetes pod we used. Therefore, an interesting feature was tested: the (original) streaming engine, which can handle tables bigger than memory (Polars version 0.19.0). Based on this experimentation, the team decided to implement Polars for all new pipelines where input tables are less than 50 GiB with stable size over time and where complexity is reasonable (without multiple joins, dozens of aggregations, or exotic functions).
Beyond a replacement for pandas
Our Polars pipelines run on managed Kubernetes infrastructure, which has several advantages compared to Apache Spark running on cloud-hosted clusters. Whereas Spark clusters typically need minutes to coldstart, as Polars works on a single machine, it is up and running in the blink of an eye. Using Kubernetes managed infrastructure within Decathlon, which is mutualized among several departments, allows us to get a pod spinning up in a matter of a minute. Therefore, most of the time, a Polars job will be completed while we are still waiting for the Spark cluster to coldstart.
Most of the time, a Polars job will be completed while we are still waiting for the Spark cluster to coldstart.
We also got some unexpected outcomes: the computation power and duration to run our Polars pipelines are insignificant compared to the size of the Kubernetes cluster, which renders our billing for Polars equal to zero. Results are summarized in Table 1.
| Tooling | Type of compute | Approximated compute launch time (min) |
|---|---|---|
| Spark cloud-hosted cluster | Multiple nodes | 8 |
| Kubernetes | Single node | 2 |
Table 1. Spark cloud-hosted cluster vs. Kubernetes on Decathlon platform
Finally, we recently put the new streaming engine to the test. A job with rapidly growing volumetry was facing Out Of Memory (OOM) errors, even with 100 GiB of RAM and 8 CPUs requested for the Kubernetes pod.
After updating Polars to version 1.27.1 and switching from ‘in-memory’ to (the new) ‘streaming’, the pipeline only required 10 GiB of RAM and 4 CPUs (table 2). This is a substantial improvement! Internal tests show that Polars can now be used for pipelines up to TiB of input data.
| Engine used | # CPUs | RAM (GiB) | Running duration |
|---|---|---|---|
| in memory engine | 8 | 100 | 2 to 3 minutes |
| streaming engine | 4 | 10 | 2 to 3 minutes |
| ratio | 2 times less | 10 times less | equivalent |
Table 2. Comparison between pipelines run using in-memory and streaming (new) engine
As a note: Running Polars on Kubernetes presents challenges. It adds a new tool to the stack, so teams need to learn how to run the container service. It may also slow down data pipeline hopping between teams. Additionally, Kubernetes requires to be managed by Data Ops and carries specific security policies. These considerations affect how Polars is rolled out within Decathlon.
Beyond the technical aspect, an important part of our interest in Polars lies in its community. The Discord channel allows users to easily share issues and ask questions about the tool. The core developers and contributors usually answer in a couple of hours. The same applies to the GitHub repository; issues are addressed, and the pace of releases allows bugs to be fixed rapidly. In our department, Polars allows us to create a community around the tool to foster collaboration and the sharing of common libraries.
Polars as part of the technical stack
Polars is now a component of the technical stack within Decathlon, alongside Apache Spark. Using Polars in specific use cases allows us to run efficient and fast pipelines, while also significantly decreasing our infrastructure billing and pipeline complexity. The release and continuous improvements of the new streaming engine may further drive us to develop more pipelines using Polars.