
Check Technologies is a Dutch multi-modal mobility provider in the Netherlands. With locations in more than 15 cities in the Netherlands, they serve over 300.000 users on a daily basis. Check is on a mission to make cities more liveable. Shared e-mopeds are a proven and effective substitute for cars and contribute to less air and noise pollution, and less congestion in cities.
In a scale up, like Check, data grows fast, especially when regularly adding new locations and vehicles to the platform. Therefore, the engineering team of Check searched for a sustainable solution to support the growth. Paul Duvenage, senior data engineer at Check Technologies, wrote an extensive technical article about their migration from pandas to Polars. The migration resulted in a significant cost saving of 25% due to a reduction in resource usage and overall speed improvement for their data pipelines. The speed improvements decrease the time from raw data to insights and make the Check Data Platform more agile.
You can learn more about the stack that is used at Check in the technical article written by Paul Duvenage. The article also provides a more detailed insight in their migration effort. You can find the full article here.
Data engineering at Check
At Check Technologies, decision making is done in a data informed way. A core enabler of this is the Check Data Platform. It allows the organization to perform various analyses, from marketing campaign performance, and shift demand forecasting to fleet-health monitoring, fraud detection, zonal & spatial analytics and more. The results from these analyses give the teams the incentives to improve existing features and create new ones.
A core component of the data platform is Airflow, an open-source workflow management platform. Airflow is essential for the data pipelines and forms the backbone of the data infrastructure. Most of the Directed Acyclic Graphs (DAGs) at Check were built with pandas. The DAGs are used to organize dependencies and relationships on how to read data from various sources (databases, S3, etc.), clean the data, and then write the data back to various destinations, most notably the data lake and data warehouse.
As Check grows, so does the amount of data that is generated. One of the DAGs that processes AppsFlyer data (user attribution & app usage data) grew so large that on busy days the engineering team started getting the dreaded SIGKILL (Airflow is out of resources) error. Scaling up the Kubernetes (k8s) cluster, to give Airflow more resources, worked for a while but this was not a long-term solution.
Migrating from pandas to Polars
Check had been exploring Polars for more than a year, starting from version 0.14.22 in October 2022, when they ran into the resource problems. Polars stood out because of its core being written in Rust, making it faster and more memory-efficient than pandas. Additionally, the Polars’ Lazy API, which defers the query execution until the last moment, presented a solution to their problem by enabling optimizations that greatly enhances performance. Initial experiments on the most problematic DAG showed a 3.3x speed improvement in execution times. This was a significant change and exceeded expectations that were set after initial experiments.
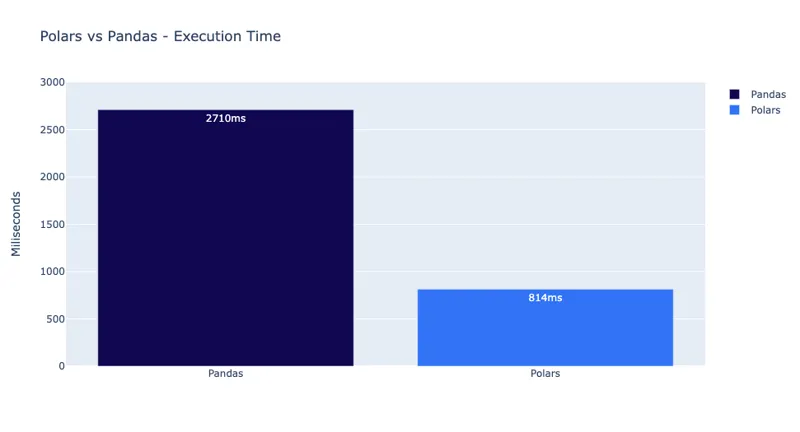
Speed improvement between pandas and Polars
Migrating 1 DAG
After implementing the solution using Polars’ Lazy API for the test, the migration of the AppsFlyer DAG was essentially complete, with only small adjustments needed for logging and notifications.
The upgraded DAG was deployed in production and monitored closely by the team for a week. The results were outstanding: not only did it operate without any issues, but it also achieved a significant increase in speed.
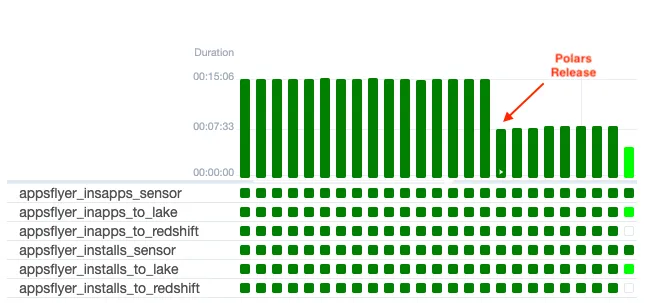
Reduction in AppsFlyer DAG execution times
Migrating 100+ DAGs
At Check, the Airflow DAGs are categorized into three types:
- Extract and Load (EL, T is done in the DWH)
- Complex Data Ingestion, Transformations or Parsing
- Other (Spatial Computation, Archival, Reporting, etc)
The majority of the DAGs fall into the EL group and share similar logic: extracting data from a database and writing it to the S3 data lake using the parquet file format. From there, the data is either loaded into the DWH or used by another downstream process. The remaining DAGs all have unique data sources but still write to the same S3 data lake.
While developing the original Lazy API solution an error was encountered that couldn’t be resolved directly. Seeking help in the Polars Discord channel, Ritchie, Polars’ author, suggested a fix, which solved the issue, and requested to log a Github issue. After logging the issue it was resolved in a matter of hours and available in the next release.
After migrating to Polars, it was observed that nearly all DAGs experienced a performance boost, with speeds doubling across the board.
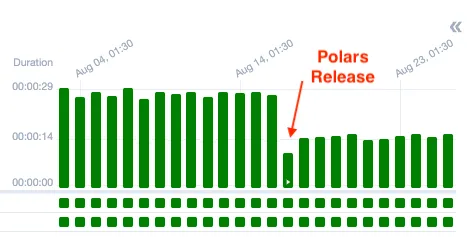
Reduction in total DAGs execution times
Results of the migration
Finally, the migration of Check’s data stack was successfully completed. With more than 100 DAGs now operational in production, the entire migration process was accomplished in less than two weeks, fitting within a single sprint, and without any interruption to normal operations. This allowed for scaling down cloud services and a more stable platform. In addition, scaling down of resources also resulted in an impressive 25% cost saving on the cloud provider bill.

Migrating from pandas to Polars was surprisingly easy. For us, the results speak for themselves. Polars not only solved our initial problem but opened the door to new possibilities. We are excited to use Polars on future data engineering projects.
Paul Duvenage
Senior Data Engineer @ Check