IMPORTANT: This post is outdated. Please check out the latest benchmark post.
Polars Decision Support (PDS) benchmarks are derived from the TPC-H Benchmarks and as such any results obtained using PDS are not comparable to published TPC-H Benchmark results, as the results obtained from using PDS do not comply with the TPC-H Benchmarks.
Polars was benchmarked against several other solutions in a derived version of the TPC-H benchmark scale factor 10. All queries are open source and up open for PR’s here. The benchmarks ran on a gcp n2-highmem-16.
This is still a work in progress and more queries/libraries will be coming soon.
Rules
The original TPC-H benchmark is intended for SQL databases and doesn’t allow any modification on the SQL of that question. We are trying to benchmark of SQL front-ends and DataFrame front-ends, so the original rules have to be modified a little. We believe that the SQL queries should be translated semantically to the idiomatic query of the host tool. To do this we adhere to the following rules:
- It is not allowed to insert new operations, e.g. no pruning a table before a join.
- Every solution must provide 1 query per question independent of the data source.
- The solution must call its own API.
- It is allowed to declare the type of joins as this fits semantical reasoning in DataFrame API’s.
- A solution must choose a single engine/mode for all the queries. It is allowed to propose different solutions from the same vendor, e.g. (sparks-sql, pyspark, polars-sql, polars-default, polars-streaming). However these solutions should run all the queries, showing their strengths and weaknesses, no cherry picking.
- Joins may not be reordered.
Notes
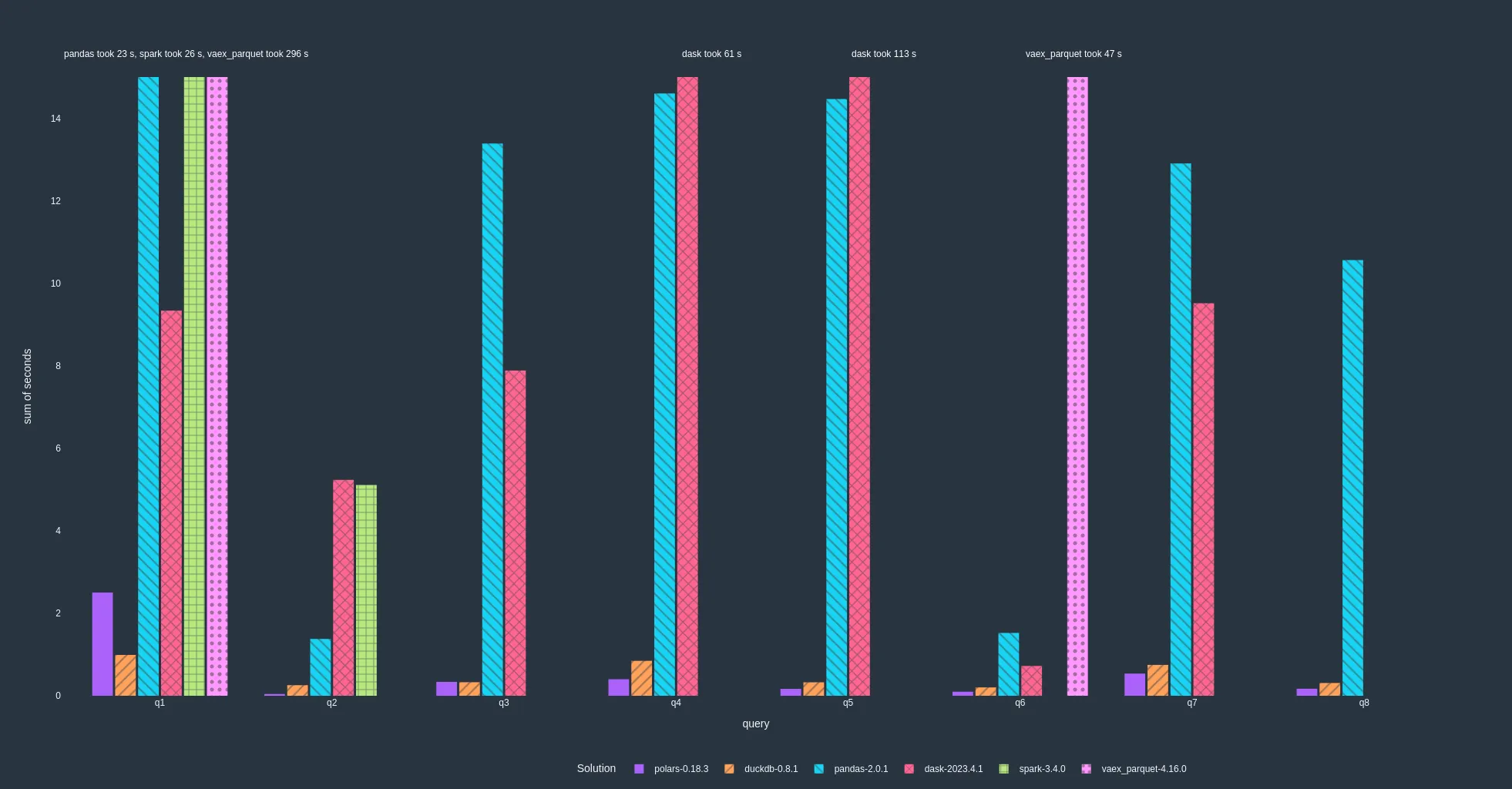
Note that vaex was not able to finish all queries due to internal errors or unsupported functionality (e.g. joining on multiple columns).
Results including reading parquet (lower is better)
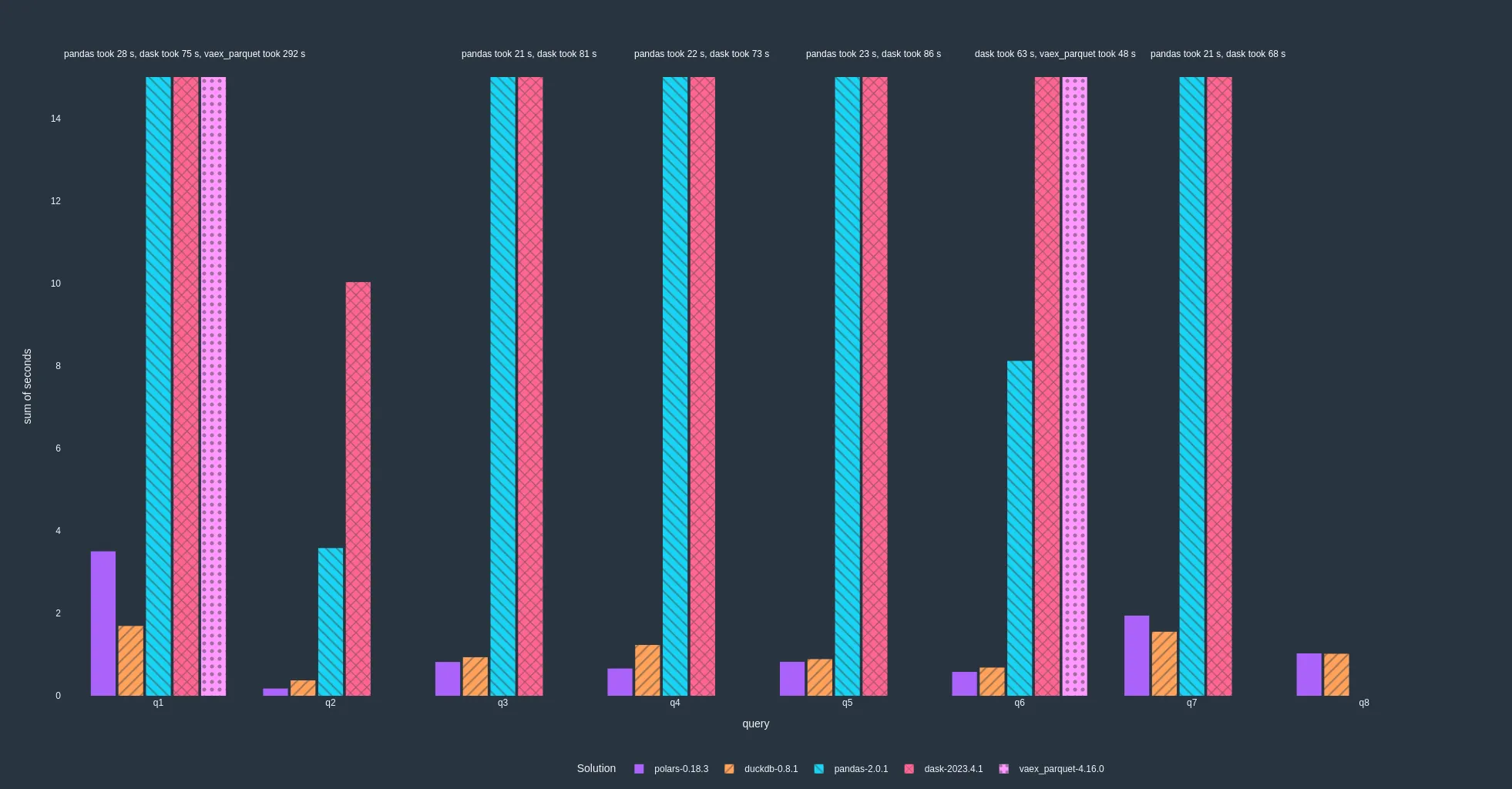
Results starting from in-memory data (lower is better)