
Preface
Through a series of experiments involving 28 common data analysis tasks (DATs) (both synthetic and from the TPC-H benchmarks) across small and large dataframes, a study found that Polars is significantly more energy-efficient than pandas, especially on large datasets. There is a strong positive correlation between energy usage and execution time across both libraries, with Polars consistently demonstrating better energy efficiency and performance.
- Polars consumed approximately 8 times less energy than pandas in synthetic DATs with large dataframes.
- For TPC-H benchmarks, Polars used about 63% of the energy required by pandas for large dataframes.
The research underlines the importance of energy efficiency and overall sustainability in the software design cycle at every organization. Polars proves to be a more energy-efficient than pandas for large-scale data analysis, due to better CPU core utilization.
Introduction
A team of researchers from Vrije Universiteit in Amsterdam, led by Ivano Malavolta, published a paper benchmarking the energy usage and performance of the pandas and Polars data analysis Python libraries.
The team benchmarked Polars and pandas to explore the correlation between energy usage and performance metrics. They did this by performing four separate experiment blocks, including eight data analytics tasks related to the official TPC-H benchmark and six synthetic tasks on both small and medium-sized datasets.
In this post, we walk through the research with Ivano and the research team to discuss the relevance, outcomes, and impact of this study.
Ivano Malavolta is an associate professor at the Software and Sustainability group of the Vrije Universiteit Amsterdam. He holds a PhD in Computer Science from the University of L’Aquila, Italy. His research activity is positioned in the following fields: data-driven software engineering, software architecture, mobile software, robotics software.
What inspired you to explore the energy usage and performance differences between Pandas and Polars?
Data manipulation is one of the most energy-intensive tasks in computing. It is also the first step before training and improving large neural network models. We believe that optimizing this step and making more energy-efficient choices could improve the overall energy footprint of these extensive solutions. When we talk about data manipulation, we must mention Python. It has been the most popular programming language, declared Number 1 according to the TIOBE index for 2024. Polars has been a relatively new addition to the data manipulation Python libraries.
Why is research into energy-efficient software development so important? What are the real world implications?
In today’s world, the software industry is consuming increasing amounts of power. Soon, the carbon footprint of energy used for significant software solutions could rival that of industries like manufacturing or aviation. This is especially concerning given the rise of, for example, large language models (LLMs), which are incredibly energy-intensive.
As a result, the energy efficiency of software choices is becoming a critical topic. Companies will soon need to prioritize energy-efficient options to reduce their environmental impact. Optimizing energy use in software development is not just about cutting costs; it’s about ensuring sustainability in a world where resources are limited and demand continues to grow. The real-world implications include mitigating climate change, reducing operational costs, and setting a precedent for responsible technology use.
Could you walk us through the process of designing your experiments? What were the key considerations in selecting the Data Analysis Tasks (DATs) for both pandas and Polars?
Our goal was to replicate the typical tasks that a data analyst would encounter when working with large datasets. The primary consideration was to include the most common operations in data manipulation. We selected a series of experiments that focused on various data analysis tasks such as reading and writing data, handling missing data, performing statistical aggregation, viewing data, and using group-by operations, among others. After selecting these tasks, we wrote scripts in both libraries, ensuring that the behavior was mirrored as closely as possible.
The experiments were conducted on an isolated server, with each experiment lasting approximately 11 hours. We ran each configuration 10 times in random order to ensure the reliability of the results. Additionally, we chose different dataframe sizes because the performance and energy efficiency could vary significantly between small and large datasets.
Can you explain the differences between the Synthetic DATs and TPCH Benchmark DATs used in your study? What unique insights did each set of tasks provide?
We decided to conduct the experiment in two separate blocks to minimize biases and capture the behavior of the two libraries in the most comprehensive way possible. The TPCH benchmark was published by the creators of Polars and has been proven to demonstrate the superiority of Polars in terms of performance. We wanted to investigate whether this performance advantage also translates to energy efficiency. To avoid bias from using only the benchmark provided by Polars’ creators, we also created six synthetic datasets based on literature. These synthetic datasets were designed to execute the most common data analysis tasks (DATs). This approach allowed us to have a more widespread and unbiased set of results.
The results showed that in synthetic data, Polars consumed about 8 times less energy than pandas for large dataframe sizes. For the TPCH benchmark, Polars used only 63% of the energy used by pandas to process the large dataframe sizes, while the small ones had a slight advantage for pandas.
Synthetic DAT’s
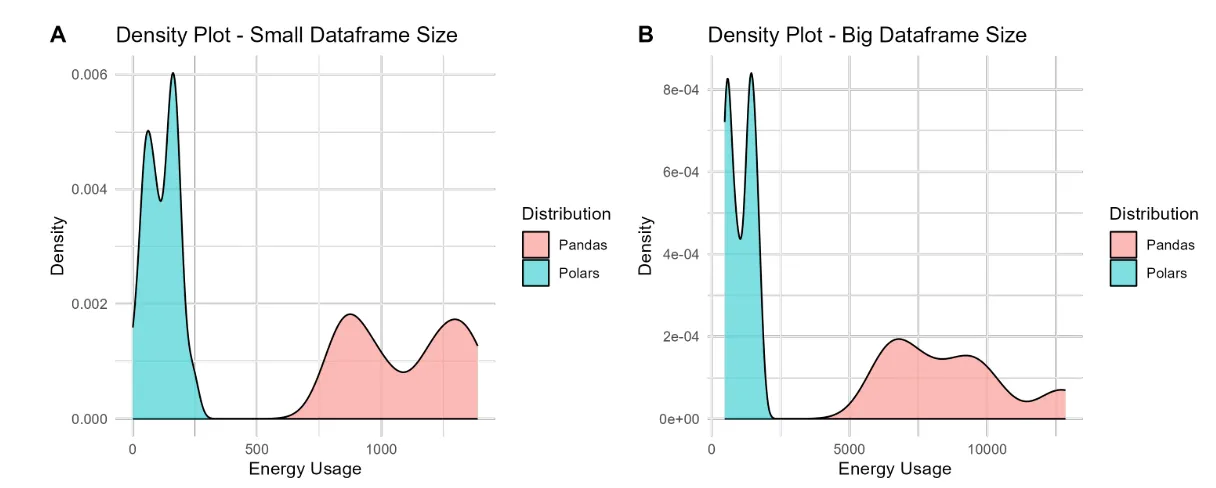
TPCH benchmark
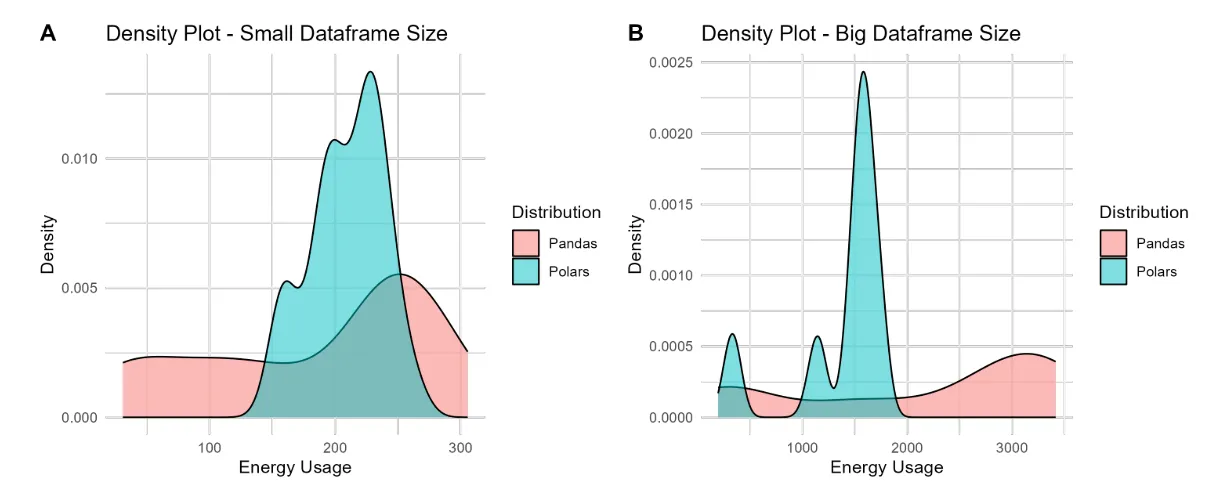
What were some of the most unexpected findings from your study? How do these findings challenge or confirm existing beliefs about pandas and Polars?
We were quite surprised by the correlation between energy efficiency and performance factors across the two libraries. Notably, we observed a statistically significant negative correlation between energy efficiency and CPU usage for the pandas library. Further research is needed to understand this fully, but it appears that Polars’ ability to harness multi-core processors for concurrent data operations significantly speeds up data processing tasks. This parallel processing capability is particularly advantageous for large datasets and complex computations, which may explain why Polars performed better in terms of energy efficiency.
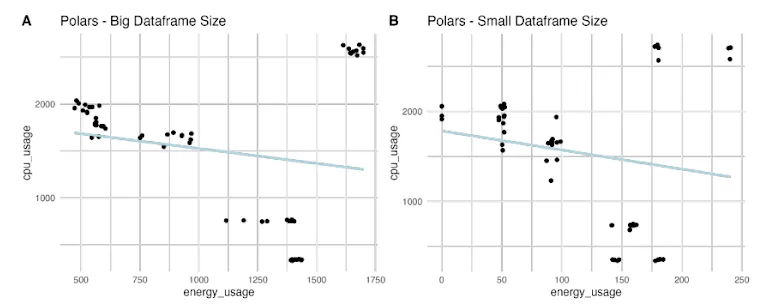
Based on your research, what practical advice would you offer to data scientists and developers choosing between Pandas and Polars for their projects?
We encourage data scientists and analysts to use Polars, as it is more energy-efficient than pandas, particularly when handling large dataframes. Our experiment also validates the claim made by Polars’ maintainers that Polars has a significantly shorter execution time compared to its competitors, especially pandas. Therefore, we recommend using Polars for performing fast, energy-efficient data analysis tasks (DATs). Furthermore, some practical advice for developers is to pay special attention to the energy costs of the libraries they choose. In the future, this will be facilitated by an energy labeling system, similar to what is already in place for household appliances, buildings, and cars. So it is rather advisable to already be aware of this process now.
Final remarks
We recommend using Polars for energy-efficient and fast data analysis, emphasizing the importance of CPU core utilization in library selection. There is still much to discover regarding the energy efficiency of data manipulation libraries. Our experiment was conducted under specific conditions and on a particular set of data analysis tasks (DATs). Therefore, when making your choices, please consider the various trade-offs relevant to your organization. Nonetheless, we strongly assert that considering energy efficiency and overall sustainability should be an integral part of the software design cycle.
The paper, including the full methodology and results, is available here: An Empirical Study on the Energy Usage and Performance of Pandas and Polars Data Analysis Python Libraries.